Series.pipe は「前の処理結果(Series)を次の関数に渡す」ための関数合成(メソッドチェーン)ユーティリティです。
可読性の高い“パイプライン”を書けるようになり、途中で自作関数・外部関数をはさみやすくなります。
# 典型例:前処理を左から右へ自然文のようにつなぐ
s = (raw_s
.pipe(clean_text) # 自作のテキストクリーナ
.pipe(pd.to_numeric, errors="coerce")
.pipe(lambda x: x.clip(0, 100)) # ちょっとした匿名関数
)基本構文
Series.pipe(func, *args, **kwargs)funcに渡された関数の第1引数にSeriesが渡され、戻り値が次のチェーンに流れます。*args,**kwargsはfuncの残りの引数にそのまま渡されます。funcはSeriesを受け取り、Series(またはチェーン可能なオブジェクト)を返すのが基本。
キーワードで受け取りたいとき(特殊タプル構文)
関数側が「データ引数名」を決め打ちしている場合は、
Series.pipe((func, "data_kw"), other_args=...)のように、("関数", "データを受け取る引数名") というタプルで指定できます。
import pandas as pd
s1 = pd.Series([1,2,3,4,5])
def scale(data=None, mean=0, std=1):
return (data - mean) / std
s2 = s1.pipe((scale, "data"), mean=s1.mean(), std=s1.std())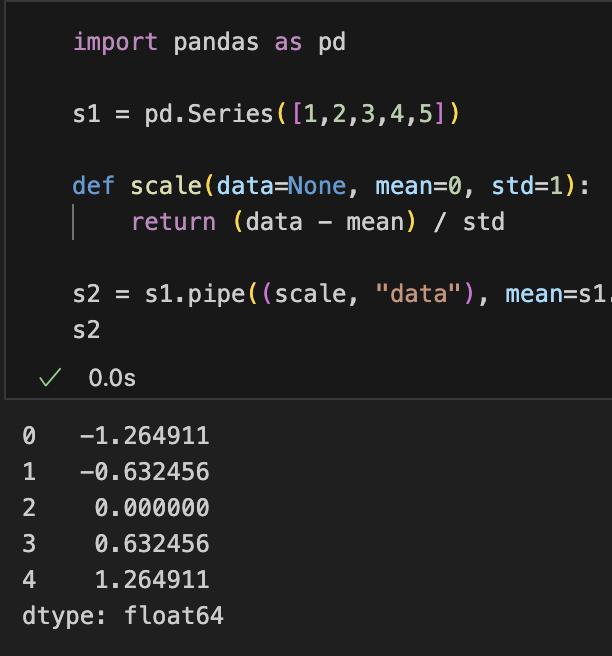
なぜ pipe を使うのか
- 読みやすい: 中間変数だらけのコードを、上から下へ流れる処理にできる
- 差し替えやすい: 一部の処理を別の関数に切り替えるのが容易
- テストしやすい: 自作関数に分離 → 単体テスト可能
- 再利用しやすい: パイプ可能な小さな関数を積み木のように組み替えられる
代表パターン
1) クリーニング→型変換→正規化
def trim_and_upper(s: pd.Series) -> pd.Series:
return s.str.replace("\u3000", " ", regex=False).str.strip().str.upper()
def winsorize(s: pd.Series, p=0.01) -> pd.Series:
lo, hi = s.quantile([p, 1-p])
return s.clip(lo, hi)
s_clean = (s_raw
.pipe(trim_and_upper) # 文字正規化
.pipe(pd.Series.replace, {"N/A": None}) # 値の置換
.pipe(pd.to_numeric, errors="coerce") # 数値化
.pipe(winsorize, p=0.01) # 外れ値抑制
.pipe(lambda x: (x - x.mean())/x.std()) # zスコア
)2) map/replace と組み合わせる
label_map = {"male": "M", "female": "F"}
s_norm = (s_label
.str.lower().str.strip()
.pipe(pd.Series.replace, {"man": "male", "woman": "female"})
.map(label_map)
)3) 小さな関数を積み木に
def drop_non_ascii(s): return s.str.replace(r"[^\x00-\x7F]+", "", regex=True)
def keep_alpha(s): return s.str.replace(r"[^A-Za-z]+", "", regex=True)
s_user = (s_user
.pipe(drop_non_ascii)
.pipe(keep_alpha)
.str.lower()
)4) デバッグ(途中結果の覗き見)
途中でログを出したいときの小技です。
def peek(head=3, title="peek"):
def _peek(s: pd.Series):
print(f"[{title}]\n{s.head(head)}")
return s
return _peek
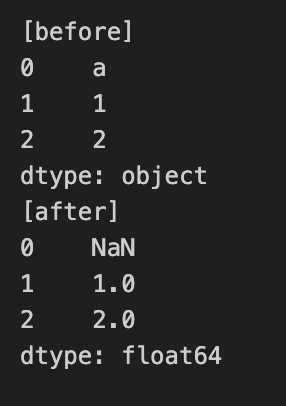
s = pd.Series(["a",1,2,3,"4"])
s2 = (s
.pipe(peek(title="before"))
.pipe(pd.to_numeric, errors="coerce")
.pipe(peek(title="after"))
)
5) 依存パラメータを同時に計算して渡す
前段の統計量を後段に渡すときもチェーンで自然に書けます。
def minmax_scale(s, lo=None, hi=None):
lo = s.min() if lo is None else lo
hi = s.max() if hi is None else hi
return (s - lo) / (hi - lo)
s_scaled = s.pipe(minmax_scale) # s自身からlo/hiを算出6) 複数戻り値の扱い
pipe 自体は1つのオブジェクトを返す想定です。複数戻り値を返す関数を挟むなら、そのままタプルで受けて pipe を区切るか、辞書やNamedTupleで返してから選択します。
def stats(s):
return {"z": (s - s.mean())/s.std(), "rank": s.rank()}
z = s.pipe(stats)["z"]応用テクニック
ラムダでメソッド呼び出しを包む
Series のメソッドに追加パラメータを渡したいだけなら、ラムダで十分です。
s2 = (s
.pipe(lambda x: x.str.replace("-", "", regex=False))
.pipe(lambda x: x.str.slice(0, 8))
)functools.partial で引数固定関数を作る
from functools import partial
scale_01 = partial(minmax_scale, lo=0, hi=1) # 意味は薄い例だが書き方の参考
s2 = s.pipe(scale_01)外部関数に“キーワードで”渡したい
先述のタプル構文を使うと、外部関数の引数名にSeriesを差し込みやすいです。
def clip_by(data=None, lower=None, upper=None):
return data.clip(lower, upper)
s2 = s.pipe((clip_by, "data"), lower=0, upper=100)apply と pipe の違いと使い分け
applyは「要素ごとに関数を適用」する道具。ベクトル化できない細粒度の変換向き。pipeは「Series全体を関数に通す」道具。工程の接着剤であり、関数合成のための文法糖。
つまり、中で使う関数の粒度が違います。Series加工の王道は「演算子・str・dt・map・replace・where/mask → それらを pipe で繋ぐ」。それで表現できない微細な変換だけ apply を使う、という順序が実務で安定します。
アンチパターン・注意点
pipeに渡す関数が副作用(inplace変更)を持つと、チェーンの見通しが悪くなるpipe内でprintデバッグを多用するとノイズが増える。必要箇所に限定- 戻り値がSeries以外(例えばスカラー)になると、その先をチェーンできなくなる。最終段以外ではSeries(またはチェーン可能な型)を返すように設計する
まとまった例(現場でよくある前処理)
import pandas as pd
def clean_amount(s: pd.Series) -> pd.Series:
return (s.str.replace(",", "", regex=False)
.str.replace("円", "", regex=False)
.pipe(pd.to_numeric, errors="coerce"))
def cap_by_quantile(s: pd.Series, p=0.01) -> pd.Series:
lo, hi = s.quantile([p, 1-p])
return s.clip(lo, hi)
def zscore(s: pd.Series) -> pd.Series:
return (s - s.mean()) / s.std(ddof=0)
amount = (raw_amount
.pipe(clean_amount)
.pipe(cap_by_quantile, p=0.01)
.pipe(zscore)
.round(3)
)このように pipe は、Series全体を扱う関数を読みやすく連結するための道具です。小さく純粋な関数(入力→出力のみ)を作り、pipe で繋ぐ、が最も威力を発揮します。