Polarsとは
Polarsは、Rustで実装された高速な列指向データフレームライブラリで、Pythonからはpolarsパッケージとして利用できます。pandasと同じ「表形式データ」を扱いますが、設計思想と内部実装が異なり、大規模データや複雑な変換を高速・省メモリで処理できるのが特徴です。
主要な特徴
- 列指向・Apache Arrow互換
- 列ごとに連続したメモリ配置を取り、ベクトル化演算に強い
- ArrowやParquetとの入出力が高速で相互運用しやすい
- Rust実装+マルチスレッド
- 並列実行でCPUコアを効率的に活用し、PythonのGILの影響を受けにくい
- Eager(即時)とLazy(遅延)両モード
- 即時: その場で結果を得る
- 遅延: クエリ計画を最適化してから実行(クエリ最適化、述語下推し、列プルーニングなど)
- 式ベースの宣言的API
- 「どう計算するか」ではなく「何を計算したいか」を
pl.col()などの式で記述でき、最適化が効きやすい
- 「どう計算するか」ではなく「何を計算したいか」を
- ストリーミング・アウトオブコア処理
- 大きなファイルをチャンクに分けて処理し、メモリ使用量を抑えられる
- 相互運用性
- pandas/NumPy/Arrow/Parquetとの相互変換が容易
- 近年は簡易的なSQLインターフェースも提供
pandasとの違い(要点)
- 実装と言語
- pandas: 主にC/pyで実装、行指向に近い操作も多い
- Polars: Rust実装の列指向、並列化・最適化が前提
- パフォーマンスとスケール
- Polarsは並列・遅延最適化・列プルーニングで大規模データに強い
- 同じメモリ量でも扱えるデータ規模が伸びやすい
- APIスタイル
- pandasは命令的に書きやすい
- Polarsは式ベースで宣言的、依存関係が明瞭で最適化が効く
- 欠点・注意点
- pandas特有の慣れた書き方がそのままでは通用しない
- 一部の長年のpandasエコシステム(特化ライブラリ)との親和性は要確認
どんなときにPolarsを選ぶか
- 数百万〜数千万行規模のデータを、ノートPCや単一マシンで高速処理したい
- ファイルベース(CSV/Parquet/IPC)中心で、ETLや特徴量作成をスムーズに回したい
- 集計や列変換が多く、パイプライン最適化の恩恵を受けたい
- 先に「計画」を最適化してから一気に実行したい(Lazyが強み)
Polarsの始め方
公式:https://docs.pola.rs/user-guide/getting-started/
Polarsをインストールする
pip install polarsバージョン確認:この記事の執筆時点では「1.33.0」です
pl.__version__
# 1.33.0データの作成
Pandasのデータフレームと同じで、辞書型の{key: value}のペアが1列に相当する
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)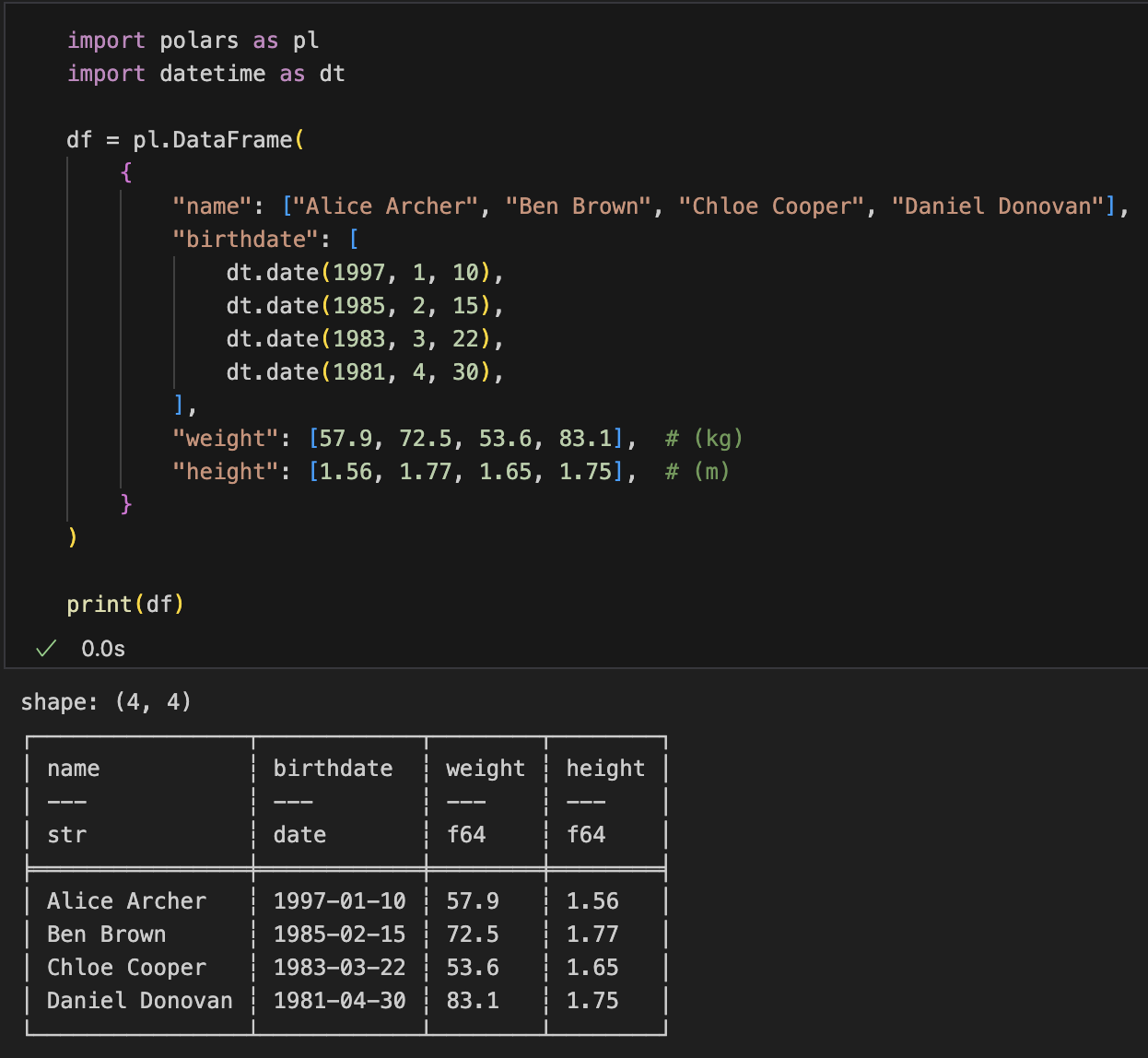
列の追加はwith_columnsで行う
pandasでは下記でOKだがPolarsではエラーになる
df["bmi"] = df["weight"] / (df["height"] ** 2)
print(df)
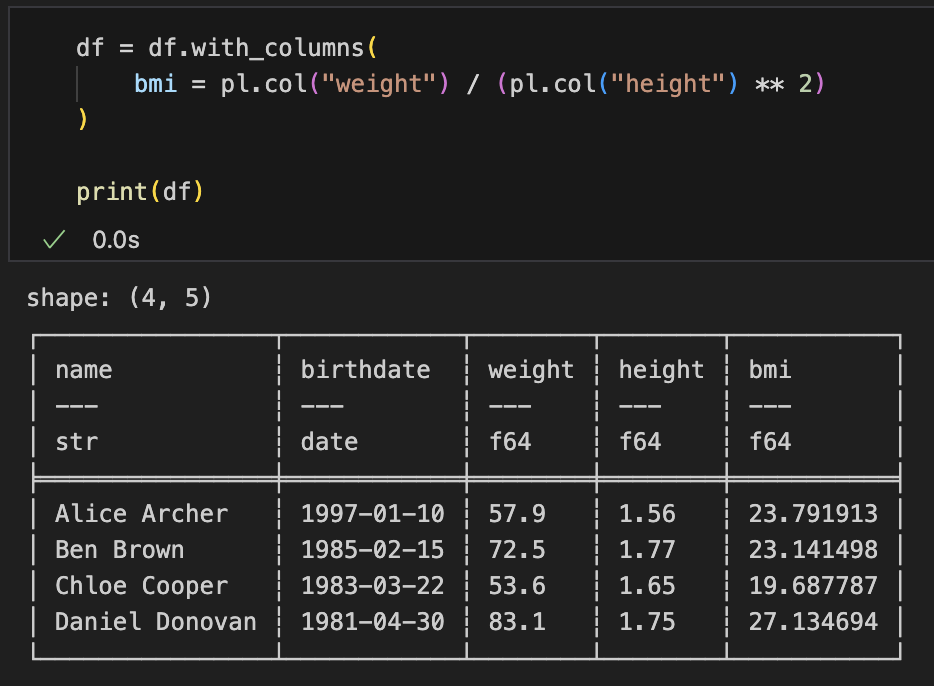
# TypeError: DataFrame object does not support `Series` assignment by indexPolars的に正しい書き方:df.with_columns(新しい列名 = 列のデータ)
df = df.with_columns(
bmi = pl.col("weight") / (pl.col("height") ** 2)
)
df["weight"] よりも pl.col("weight")の方がいい理由
Polarsでは df["weight"] より pl.col("weight") を使うのが基本です。理由は「式(Expr)」として最適化可能に書くためです。
何が違うのか
df["weight"]- その場で「Series(具体的なデータ)」を取り出します。
- 取り出した時点で実体化され、以降の最適化(列プルーニング、述語下推し、ストリーミングなど)の恩恵を受けにくくなります。
- 代入(
df["bmi"] = ...)には使えないため、写経的にpandasと同じ発想で書くとエラーになります。
pl.col("weight")- 「weight列を使う」という宣言だけを表す式(Expr)です。具体的なデータはまだ取り出しません。
with_columns,select,filter,groupby/aggなどの中で、Polarsの実行エンジンがクエリ計画に組み込み、並列化・最適化してから実行します。- LazyFrame(
scan_*で始める遅延処理)で必須かつ本領発揮します。Eagerでも最適化の土台になります。
なぜ「df」ではなく「pl」で列を指定できるのか
dfというオブジェクトの列を指定するのに、plで列名を指定できるのはおかしいのでは?
⇨df.with_columns()の中に書くから、このdfの列のことだよというのは判定できる
with_columns(やselect、filter、group_byなど)に書いたpl.col("weight")は、その「式が評価されるフレーム(= そのときのdf / LazyFrame)」のスキーマに対して解決されます。
もしdf1とdf2があって、両方にweight列がある場合、pl.col("weight")と書くとどうなる?
with_columns内では、そのdfに存在する列名だけが解決対象になります- もし
join直後などで同名列が同一フレームに複数ある場合は、Polarsが右側にsuffixを付けるので、以降は"weight"と"weight_right"のように一意な列名で参照します(suffixは自分で指定可能)。 - 複数のデータフレームを同時に参照したい処理は、まず
join/hstack/concat等で1つのフレームにまとめ、衝突しない名前(renameやsuffix、Struct化)にしてからpl.col(...)で参照します。 - Lazyでも同じで、
with_columnsやselectがかかっているそのLazyFrameのスキーマが解決先になります。
最小例
df1 = pl.DataFrame({"id":[1,2], "weight":[70,60]})
df2 = pl.DataFrame({"id":[1,2], "weight":[68,62]})
out = (
df1.join(df2, on="id", suffix="_r")
.with_columns(diff = pl.col("weight") - pl.col("weight_r"))
)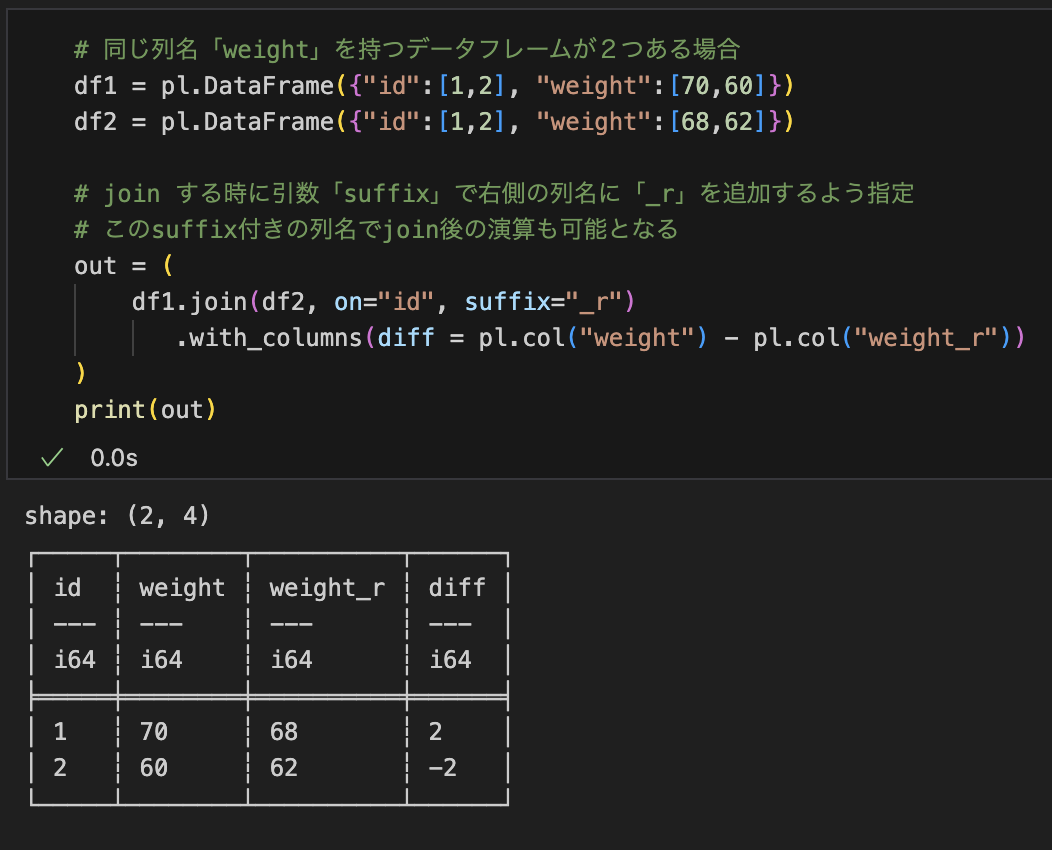
このように「式が評価されるフレーム」が文脈になっており、そこで一意に解決できるように列名を整えるのがPolarsの流儀です。
Structとは
Structは、Polarsにおける「入れ子の列(ネストした1列)」で、複数のフィールド(名前付きスカラー)を1つの列にまとめたデータ型です。イメージとしては「各行に辞書({key: value})が入っている1列」や「サブテーブルを1セルに格納している列」に近いものです。
Structで何ができるか・何が嬉しいか
- 列の“名前空間”を作れる
関連する列をひとまとめにして、列名の衝突や煩雑さを避けられる - JSON/Parquetなどのネスト構造を自然に表現できる
読み書きの相性がよい(Arrow準拠のネスト型) - 集約結果を1列にパッケージ化して持ち回り、必要なときに展開(unnest)できる
パイプラインが読みやすくなる
Structの作り方
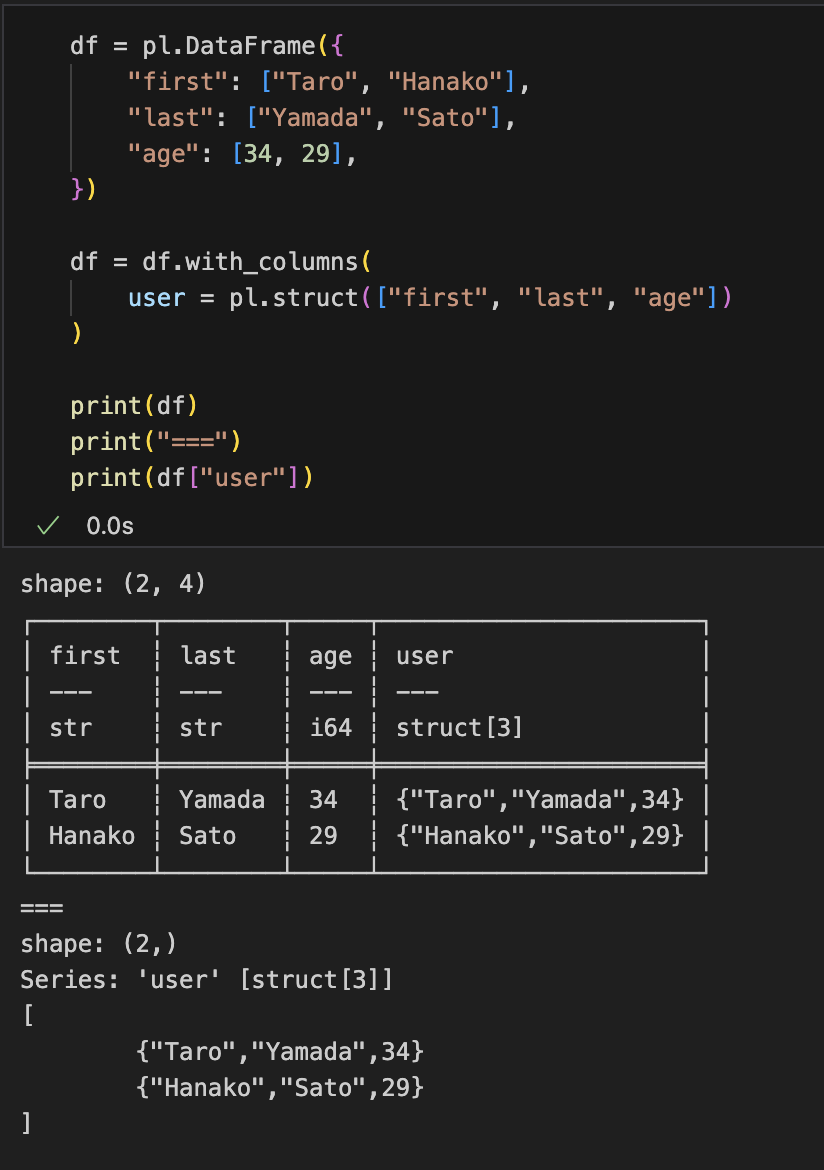
既存の複数列をStructにまとめる:
import polars as pl
df = pl.DataFrame({
"first": ["Taro", "Hanako"],
"last": ["Yamada", "Sato"],
"age": [34, 29],
})
df = df.with_columns(
user = pl.struct(["first", "last", "age"])
)
Pythonの辞書相当からStructを作る(行ごとに辞書がある場合):
df = pl.from_dicts([
{"id": 1, "meta": {"city": "Tokyo", "tz": "Asia/Tokyo"}},
{"id": 2, "meta": {"city": "Osaka", "tz": "Asia/Tokyo"}},
])
# "meta" は最初から Struct 列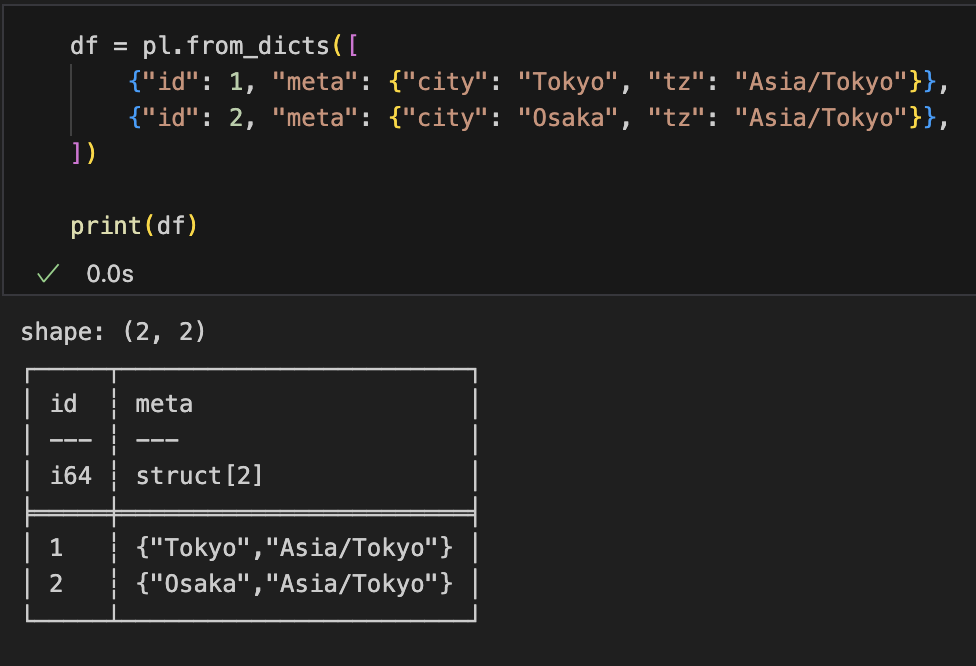
フィールドへのアクセス
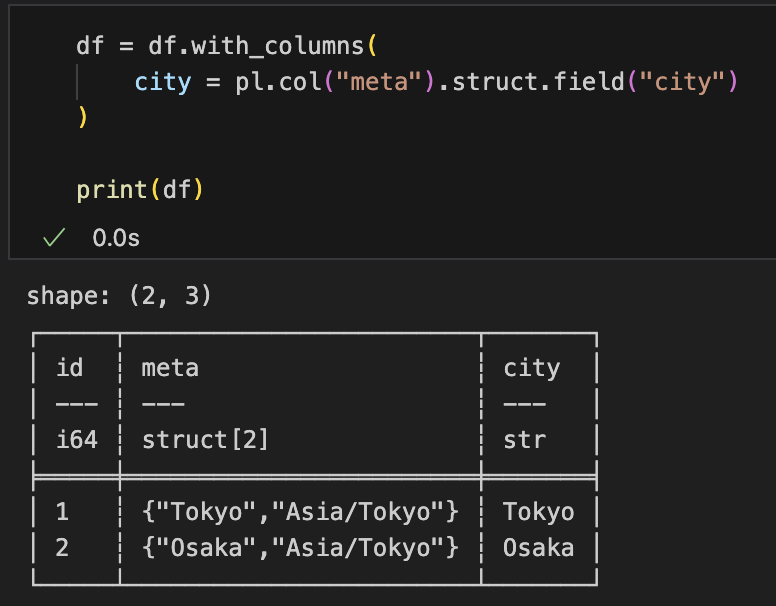
Struct列の特定フィールドを取り出す:
df = df.with_columns(
city = pl.col("meta").struct.field("city")
)
入れ子が深い場合も同様に.struct.field(...)を重ねます。
展開(Struct → 複数列): unnest
Struct列を元の複数列に戻す
df = pl.DataFrame(
{
"before": ["foo", "bar"],
"t_a": [1, 2],
"t_b": ["a", "b"],
"t_c": [True, None],
"t_d": [[1, 2], [3]],
"after": ["baz", "womp"],
}
).select("before", pl.struct(pl.col("^t_.$")).alias("t_struct"), "after")
print(df)
print("↓")
print(df.unnest("t_struct"))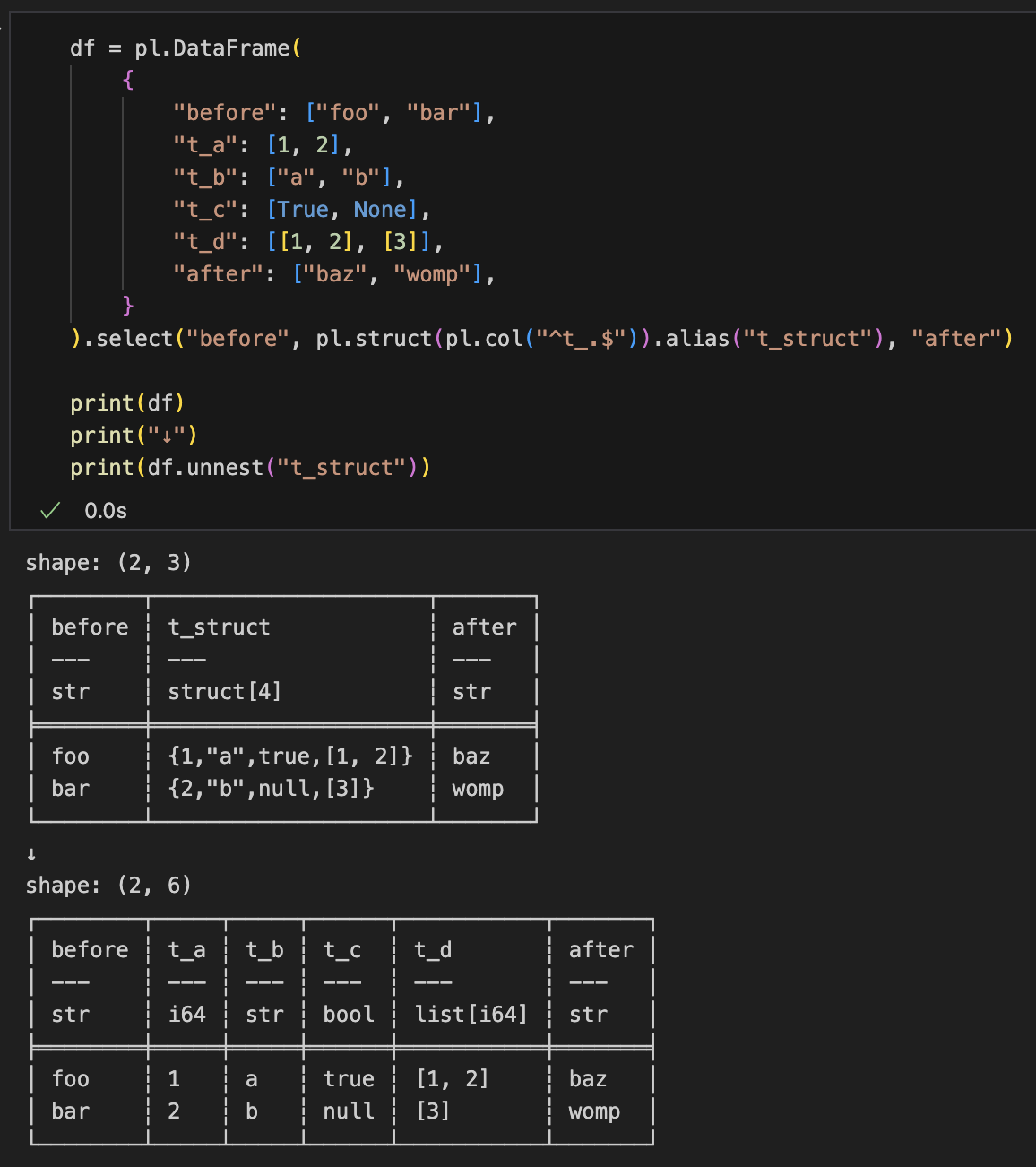
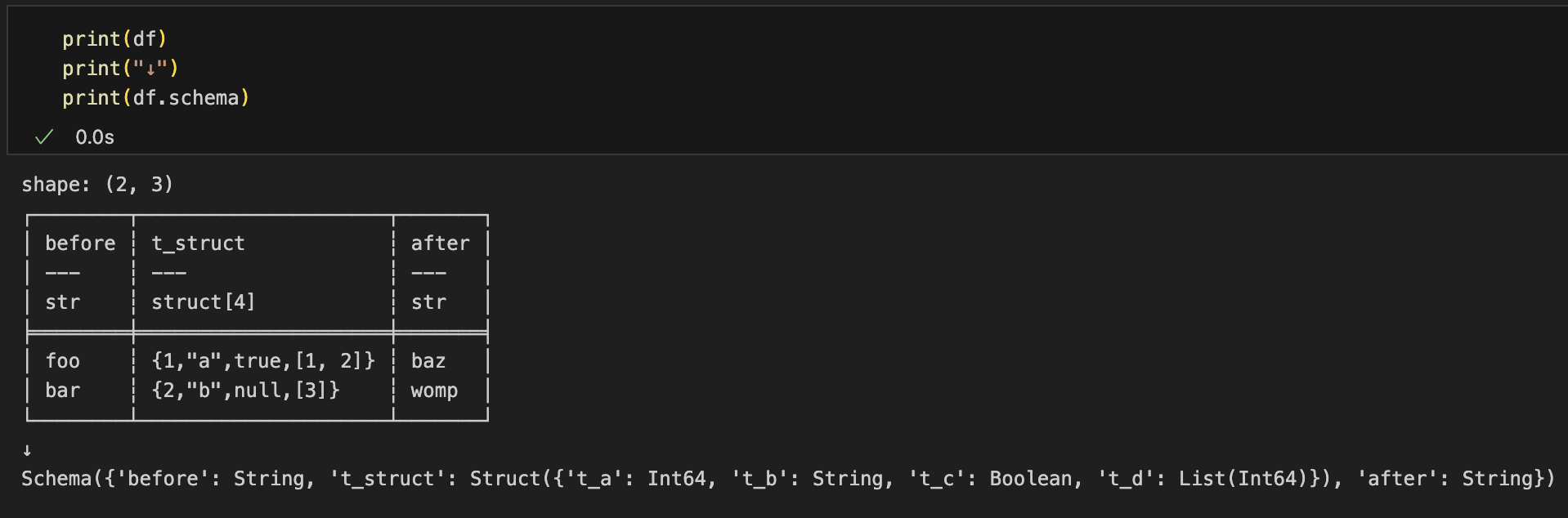
Structのフィールド名を調べる:df.schema
補足
- List型(同質の値の並び)とStruct型(異なる名前付きフィールドの集合)は別物。
異種の情報をまとめたいならStruct、同種の可変長ならListが適します。 - Structは「1列」なので、列選択や移動・フィルタの対象として扱いやすく、必要時のみ展開できます。
df.with_columnsの使い方まとめ
with_columnsは「列の追加・更新」を宣言的に書くための中核APIです。ポイントは式(Expr)で列を定義し、エンジンに最適化させることです。EagerでもLazyでも同じ書き方で使えます。
最小例:列の追加・更新
import polars as pl
df = pl.DataFrame({"weight": [70, 60], "height": [1.75, 1.62]})
# 追加(キーワード記法)
df = df.with_columns(
bmi = pl.col("weight") / (pl.col("height") ** 2)
)
# 更新(同名を再定義)
df = df.with_columns(
weight = pl.col("weight").cast(pl.Float64)
)aliasで列名を付ける(位置引数のとき)
df = df.with_columns(
(pl.col("weight") / (pl.col("height") ** 2)).alias("bmi")
)「位置引数」とは、キーワード指定せずに引数を渡すこと。つまり列名の付け方は2種類ある
1)キーワード記法:新しい列名=式
2)位置引数:(式).alias("新しい列名")
スカラー・Python変数との組み合わせ
target_bmi = 22
df = df.with_columns(
# スカラーは pl.lit で式化(数値なら自動式化も働きますが明示が安全)
ideal_weight = pl.lit(target_bmi) * (pl.col("height") ** 2)
)条件分岐・欠損/ゼロ割対策
df = df.with_columns(
bmi = pl.when(pl.col("height") > 0)
.then(pl.col("weight") / (pl.col("height") ** 2))
.otherwise(None)
)
# 欠損補完や同等の処理も式で
df = df.with_columns(
height_filled = pl.col("height").fill_null(strategy="forward")
)複数列を一気に作る
df = df.with_columns(
# 位置引数で複数Expr
(pl.col("weight") / (pl.col("height") ** 2)).alias("bmi"),
(pl.col("height") * 100).alias("height_cm"),
)
# あるいはキーワードで並べる
df = df.with_columns(
bmi = pl.col("weight") / (pl.col("height") ** 2),
height_cm = pl.col("height") * 100,
)selectの使い方
基本構文:SQLのSELECTに近い感覚
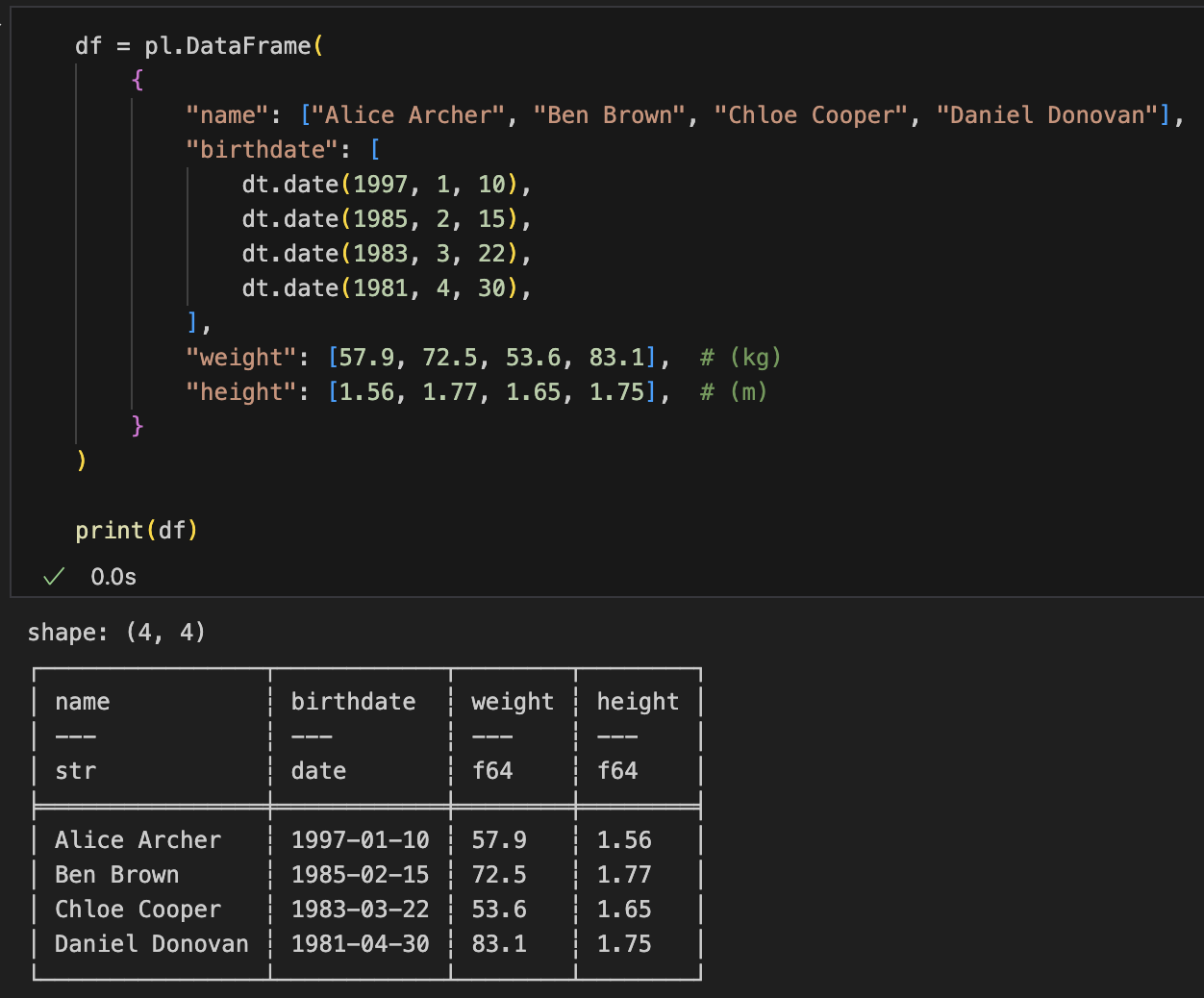
最初のサンプルデータ
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
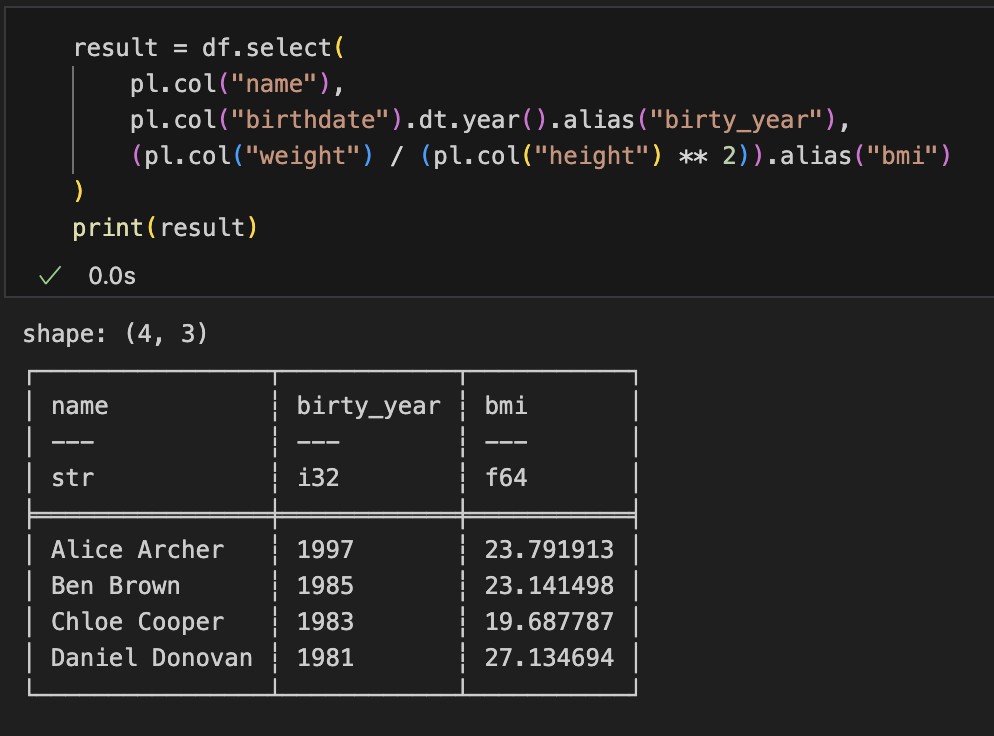
ここからname、生まれた年、BMIのデータフレームを作る
result = df.select(
pl.col("name"),
pl.col("birthdate").dt.year().alias("birty_year"),
(pl.col("weight") / (pl.col("height") ** 2)).alias("bmi")
)
これはPostgreSQLで下記のように再現できる
WITH df(name, birthdate, weight, height) AS (
VALUES
('Alice Archer', DATE '1997-01-10', 57.9, 1.56),
('Ben Brown', DATE '1985-02-15', 72.5, 1.77),
('Chloe Cooper', DATE '1983-03-22', 53.6, 1.65),
('Daniel Donovan',DATE '1981-04-30', 83.1, 1.75)
)
SELECT
name,
EXTRACT(YEAR FROM birthdate)::int AS birth_year,
weight / POWER(height, 2) AS bmi
FROM df;「expression expansion」とは
直訳すると「式の拡張」。1つの式を“複数列セレクタ”に適用すると、その式が各列に自動的に展開される仕組みです。
つまり「1つの式で、複数の列を一括処理できる」ということ
下記の例ではweightとheightの2列に対して一つの式を使い回している
result = df.select(
pl.col("name"),
(pl.col(["weight", "height"]) * 0.95).round(2).name.suffix("-5%"),
)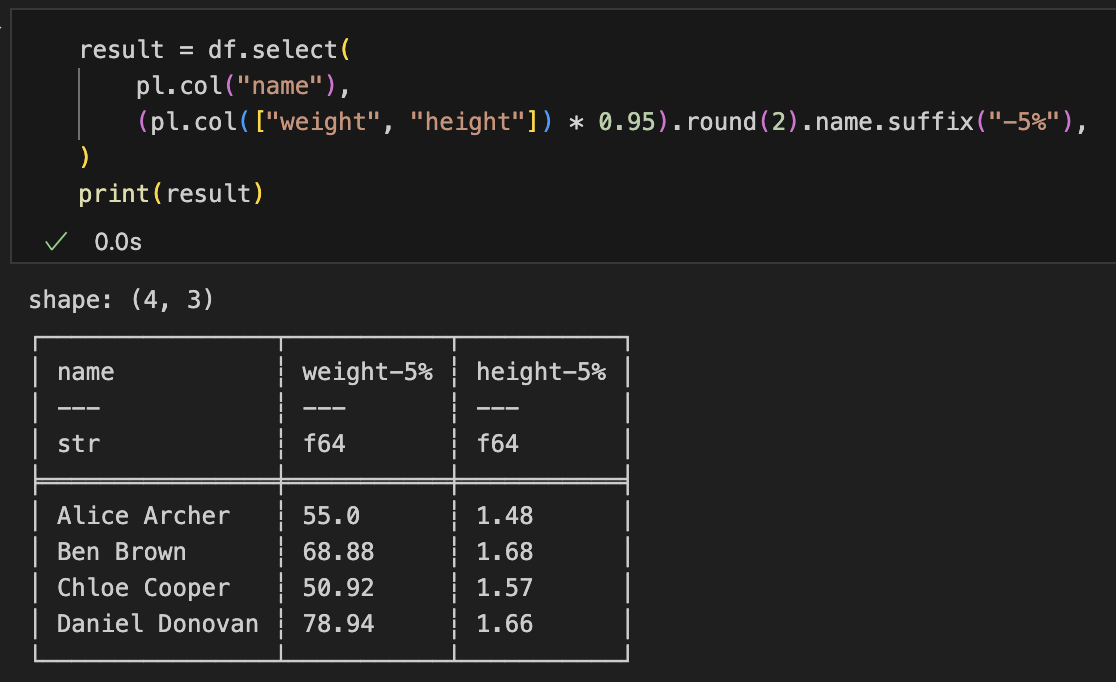
この例では、pl.col(["weight", "height"]) が2列を選択し、* 0.95 と round(2) が両方に適用され、最後に .name.suffix("-5%") がそれぞれの列名に接尾辞を付けます。出力は概念的に weight-5% と height-5% の2列が追加(または選択)された形になります。
補足
- セレクタは名前リストのほか、ワイルドカードや正規表現、型ベースのセレクタが使えます。
- 例:
pl.col("^feat_.*$"),import polars.selectors as cs; pl.col(cs.numeric())
- 例:
.name.suffix(...)や.name.prefix(...)は、拡張された各列にまとめてリネームを適用できます。
その他の主な操作
filterの使い方
df.filter()の中に式を書くだけ
result = df.filter(pl.col("birthdate").dt.year() < 1990)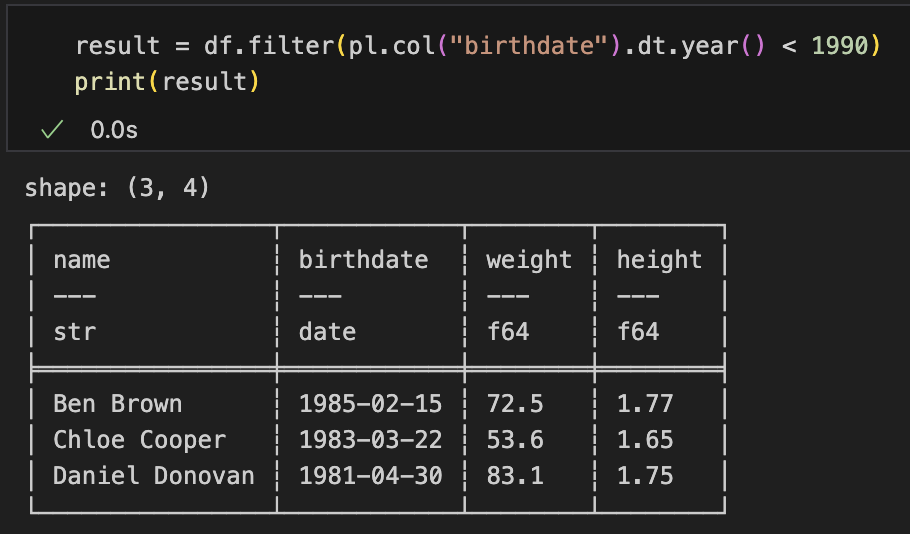
カンマ区切りで複数のフィルターを指定できる(AND条件となる)
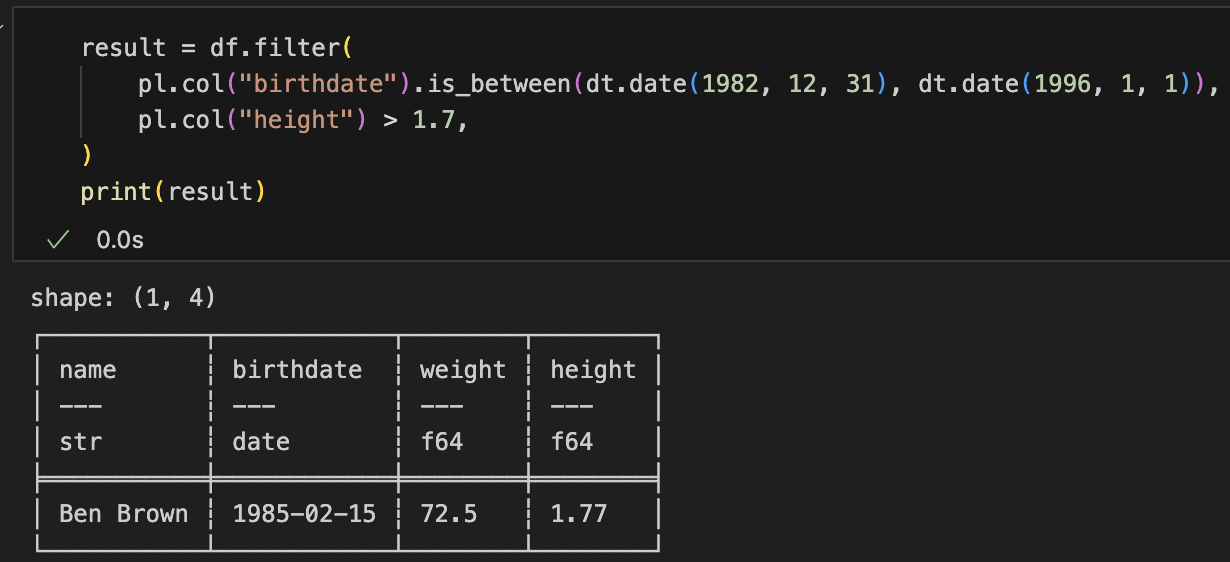
result = df.filter(
pl.col("birthdate").is_between(dt.date(1982, 12, 31), dt.date(1996, 1, 1)),
pl.col("height") > 1.7,
)
group_byの使い方
df.group_by()のあとに集計関数をつなげる。maintain_order=Trueは並び順の維持の指定。処理としては重いので不要ならつけない方がいい
result = df.group_by(
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
maintain_order=True,
).len()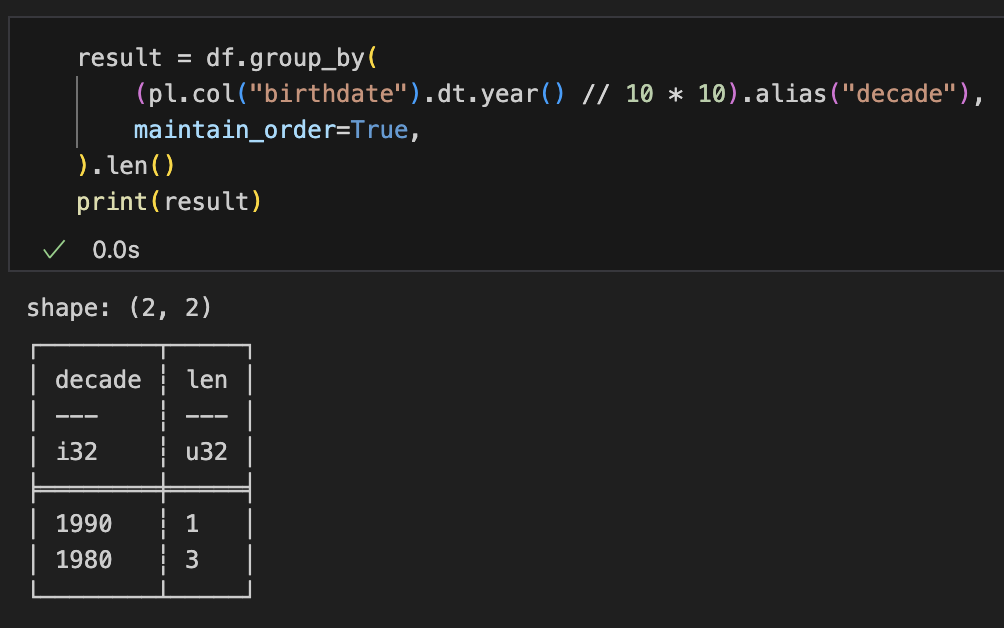
agg関数でグループ化後にどんな集計をするか細かく定義できる
reuslt = df.group_by(
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
).agg(
pl.len().alias("sample_size"),
pl.col("weight").mean().round(2).alias("avg_weight"),
pl.col("height").max().alias("tallest")
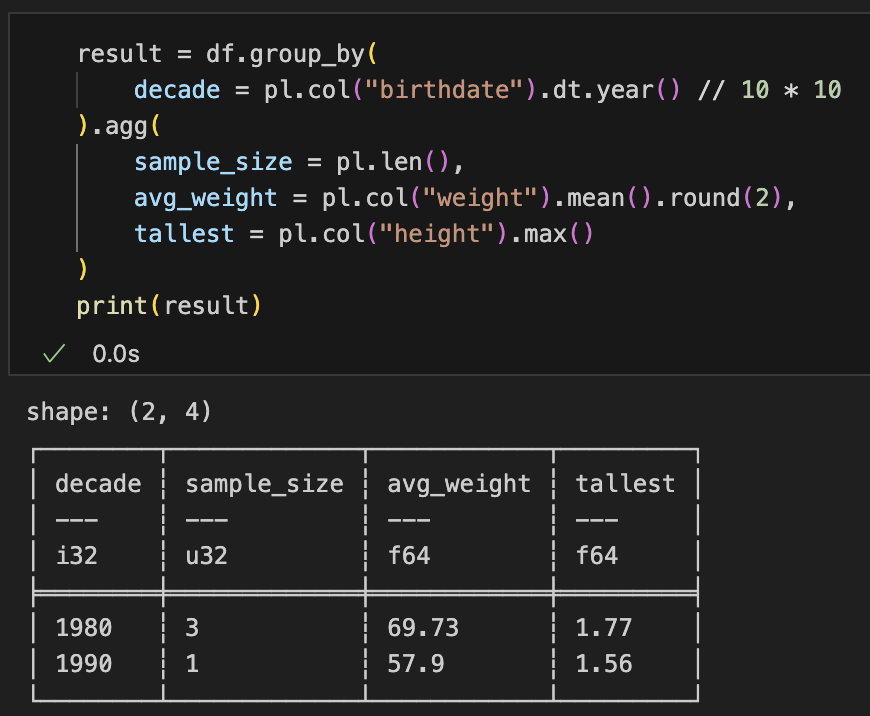
)キーワード記法の場合
result = df.group_by(
decade = pl.col("birthdate").dt.year() // 10 * 10
).agg(
sample_size = pl.len(),
avg_weight = pl.col("weight").mean().round(2),
tallest = pl.col("height").max()
)
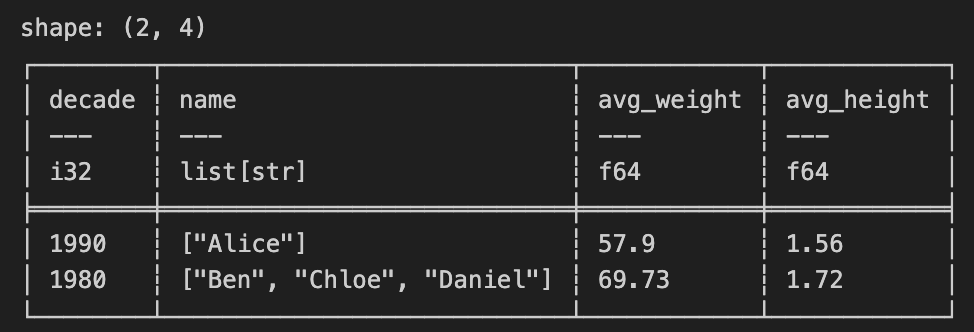
複雑なクエリ
コンテキストとその中にある式を連結して複雑なクエリを書くことができる
result = (
df.with_columns(
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
pl.col("name").str.split(by=" ").list.first()
)
.select(
pl.all().exclude("birthdate")
)
.group_by(
pl.col("decade"),
maintain_order=True
)
.agg(
pl.col("name"),
pl.col("weight", "height").mean().round(2).name.prefix("avg_")
)
)
joinの使い方
Polarsにはデータフレームを結合するアルゴリズムが複数ある。下記はnameをキーにして左外部結合する例
df2 = pl.DataFrame(
{
"name": ["Ben Brown", "Daniel Donovan", "Alice Archer", "Chloe Cooper"],
"parent": [True, False, False, False],
"siblings": [1, 2, 3, 4]
}
)
print(df.join(df2, on="name", how="left"))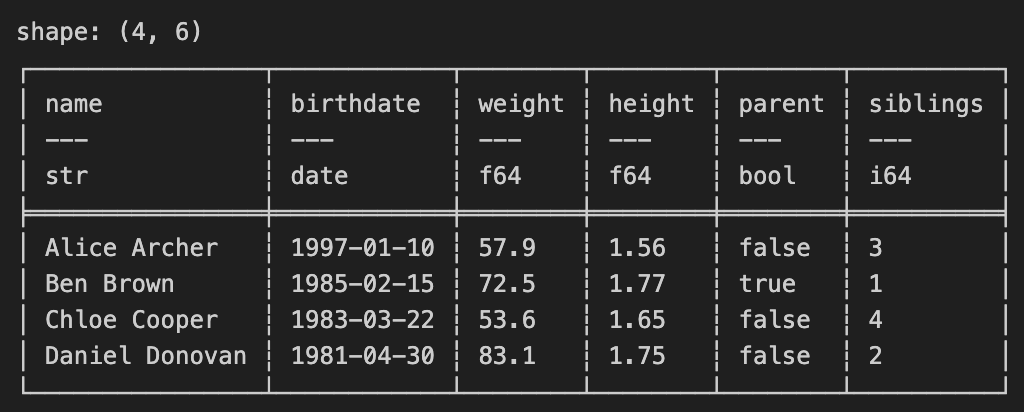
もっと詳しい情報:Joins
concatの使い方
df3 = pl.DataFrame(
{
"name": ["Ethan Edwards", "Fiona Foster", "Grace Gibson", "Henry Harris"],
"birthdate": [
dt.date(1977, 5, 10),
dt.date(1975, 6, 23),
dt.date(1973, 7, 22),
dt.date(1971, 8, 3),
],
"weight": [67.9, 72.5, 57.6, 93.1],
"height": [1.76, 1.6, 1.66, 1.8]
}
)
print(pl.concat([df, df3], how="vertical"))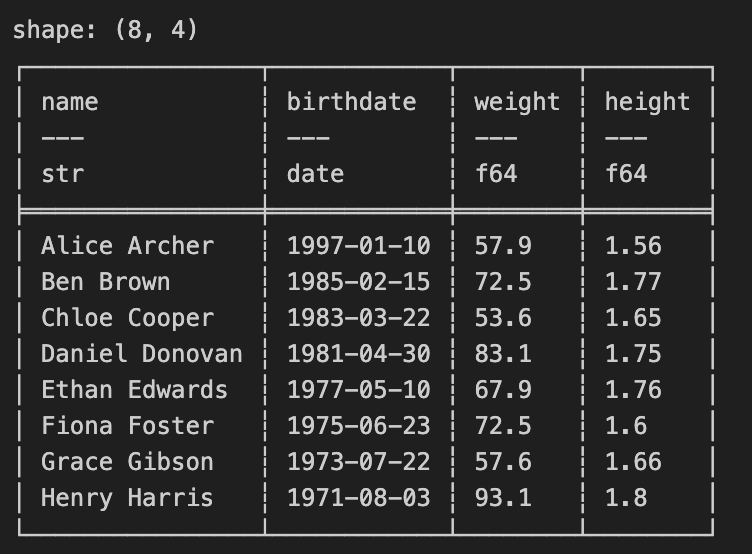
もっと詳しい情報:Concatenation