df.loc[...] の中には「行ラベルを指定するための インデックス(またはブール条件)」を入れられるので、groupby で得られる インデックス(idxmin/idxmaxなど) をそのまま渡すことができます。apply よりも高速かつシンプルに書ける王道テクニックです。
例:各グループで最小の行を取る
df = pd.DataFrame(
{
"animal": "cat dog cat fish dog cat cat".split(),
"size": list("SSMMMLL"),
"weight": [8, 10, 11, 1, 20, 12, 12],
"adult": [False] * 5 + [True] * 2,
}
)
df.loc[df.groupby("animal")["weight"].idxmin()]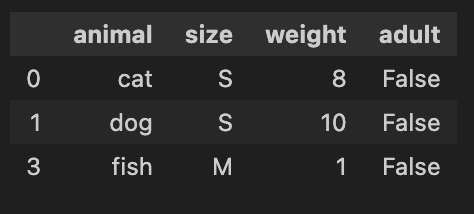
df.groupby("animal")["weight"].idxmin()は「各グループでweightが最小の行のインデックス」を返す- そのインデックスを
df.loc[...]に渡すと、該当行だけが抜き出せる - 「groupbyがlocの中で動いている」わけではなく、単に「groupby結果のインデックスをlocに渡している」と考えると整理しやすい
応用パターン
最大の行を取りたい場合
df.loc[df.groupby("animal")["weight"].idxmax()]特定の列だけ表示したい場合
idx = df.groupby("animal")["weight"].idxmax()
df.loc[idx, ["animal", "weight"]]行インデックスを返すカスタム関数を自作する
「idxmin() / idxmax() のように、条件付きでグループごとの行インデックスを返す関数」をいろいろ作っておくと、グループごとに代表行を柔軟に選べるようになります。
たとえば 「最大値の1つ手前の行(= Max値の-1)」 を返す関数を考えてみましょう。
基本の考え方
groupby.applyを使って、各グループを受け取るsubseries.nlargest(n)で上位n件を取れる- そのインデックスの2番目を返す(0番目が最大、1番目が「最大の次」)
実装例
import pandas as pd
def idxsecondmax(subseries: pd.Series):
"""各グループで2番目に大きい値のインデックスを返す"""
if len(subseries) < 2:
return subseries.idxmax() # データが1件しかなければmaxで代用
return subseries.nlargest(2).index[1]
# サンプルデータ
df = pd.DataFrame({
"animal": ["cat","cat","cat","dog","dog"],
"weight": [3, 5, 4, 7, 2],
})
idx = df.groupby("animal")["weight"].apply(idxsecondmax)
out = df.loc[idx]
print(out)処理のパターン集
代表行抽出(最小・最大)
# 各animalで最小weightの行
idx = df.groupby("animal")["weight"].idxmin()
out = df.loc[idx]タイブレークを制御したい場合はあらかじめ並べておくと安定します。
idx = (
df.sort_values(["animal", "weight", "timestamp"])
.groupby("animal")["weight"].idxmin()
)
df.loc[idx]Top-N抽出(各グループ上位k行)
# 先に全体を並べてから head(k)
out = (
df.sort_values(["animal", "score"], ascending=[True, False])
.groupby("animal")
.head(3)
)順位で絞る書き方もあります。
rank = df.groupby("animal")["score"].rank(method="first", ascending=False)
out = df.loc[rank.le(3)]グループ基準の条件代入(loc × transform)
med = df.groupby("animal")["weight"].transform("median")
# 各グループの中央値×1.5を超える行をフラグ
df.loc[df["weight"] > med * 1.5, "is_heavy"] = Truezスコアで外れ値をマークする例。
g = df.groupby("animal")["weight"]
z = (df["weight"] - g.transform("mean")) / g.transform("std")
df.loc[z.abs() > 3, "outlier"] = True「最大の一つ手前」などのカスタム代表行
# 各animalで2番目に大きいweightの行インデックス
idx = df.groupby("animal")["weight"].apply(
lambda s: s.nlargest(2).index[1] if len(s) > 1 else s.idxmax()
)
df.loc[idx]各グループで最初/最後の非欠損行
# 最初の非欠損
mask = df["value"].notna()
idx = mask.groupby(df["animal"]).apply(lambda m: m.idxmax() if m.any() else pd.NA).dropna()
first_valid = df.loc[idx]
# 最後の非欠損(逆順で同様)
mask_rev = df.iloc[::-1]["value"].notna()
idx_rev = mask_rev.groupby(df.iloc[::-1]["animal"]).apply(lambda m: m.idxmax() if m.any() else pd.NA).dropna()
last_valid = df.loc[df.index[::-1][idx_rev]]グループ内の最大変化点を拾う
diff = df.groupby("animal")["weight"].diff()
idx = diff.abs().groupby(df["animal"]).idxmax()
df.loc[idx]複合スコアで代表行
score = 0.7 * df["acc"] + 0.3 * df["speed"]
idx = score.groupby(df["model"]).idxmax()
best = df.loc[idx, ["model", "acc", "speed", "params"]]しきい値を初めて超えた時点を取る
cs = df.groupby("user")["sales"].cumsum()
idx = cs.ge(1000).groupby(df["user"]).idxmax()
reached = df.loc[idx].dropna(subset=["user"]) # 未達のグループはNaNになるので落とす重複キーで最初の行だけ残す(事前ソートで規則を決める)
base = df.sort_values(["animal", "weight", "timestamp"])
dedup = base.loc[base.groupby("animal").head(1).index]
# または drop_duplicates("animal", keep="first") でも可条件を満たす行だけを各グループで一つ拾う
cond = df["quality"] >= 80
idx = cond.groupby(df["batch"]).apply(lambda s: s[s].index[0] if s.any() else pd.NA).dropna()
picked = df.loc[idx]