PandasのSeriesオブジェクトとは
pandas.Series は 1次元の配列状のデータ構造 で、NumPyの配列に似ていますが、ラベル付きのインデックスを持てるのが特徴です。表形式データの1列に相当することが多く、Pandasの基本的な構成要素のひとつです。
基本構造
- 値(values): 実際のデータを格納する部分。NumPy配列として保持されます。
- インデックス(index): 各要素に対応するラベル。整数や文字列などを自由に設定可能です。
例:
import pandas as pd
s = pd.Series([10, 20, 30], index=["a", "b", "c"])
print(s)出力:
a 10
b 20
c 30
dtype: int64主な特徴
1. インデックス付き
インデックスを使ってデータにアクセスできます。
print(s["b"]) # 202. NumPy互換
多くのNumPyの関数がそのまま使えます。
import numpy as np
print(np.mean(s)) # 20.03. 自動アラインメント
インデックスに基づいて演算を行います。
s1 = pd.Series([1, 2, 3], index=["a", "b", "c"])
s2 = pd.Series([10, 20, 30], index=["b", "c", "d"])
print(s1 + s2)出力:
a NaN
b 12.0
c 23.0
d NaN
dtype: float644. データ型(dtype)
1つのSeriesは基本的に単一のdtypeを持ちます(int, float, str, objectなど)。
よく使うメソッド・属性
s.values: 値(NumPy配列)s.index: インデックスs.head(n): 先頭n件を表示s.tail(n): 末尾n件を表示s.describe(): 統計量の要約を表示(数値データのみ)s.isnull()/s.notnull(): 欠損値チェック
使用例
辞書から作成
data = {"apple": 3, "banana": 5, "orange": 2}
fruits = pd.Series(data)
print(fruits)条件フィルタ
print(fruits[fruits > 2])統計処理
print(fruits.mean()) # 平均
print(fruits.sum()) # 合計まとめ
SeriesはPandasの基本データ構造で、インデックス付きの1次元配列。- インデックスで要素アクセスやデータ整合が可能。
- NumPyと統計関数がシームレスに使える。
- データ解析や前処理の基礎になる。
Seriesのコンストラクタ
公式:https://pandas.pydata.org/docs/reference/api/pandas.Series.html#pandas.Series
class pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=<no_default>)data
Seriesに格納するデータを指定します。サポートされる型は多岐にわたり、以下のようなものがあります。
- スカラー値(例:
5)
→indexが指定されている場合、その長さに応じて同じ値で埋められます。 - 配列やリスト(例:
[1, 2, 3]) - NumPy配列(
np.array) - 辞書型(キーがインデックス、値が要素として扱われる)
- 他のSeries
index
Seriesのインデックス(ラベル)を指定します。
- デフォルトは
RangeIndex(0, 1, 2, ...)です。 - 指定した場合、
dataの要素と長さが一致している必要があります(ただしdataが辞書ならキーと一致する部分だけ使用される)。
pd.Series([10, 20, 30], index=["a", "b", "c"])dtype
Seriesのデータ型を指定します。
- デフォルトでは、
dataの内容から自動的に推定されます。 - 明示的に
dtype="float64"のように指定することも可能。
pd.Series([1, 2, 3], dtype="float32")name
Seriesに名前を付けるための引数です。
- これにより、DataFrameに列として組み込む際に列名として扱われます。
- デフォルトは
None
s = pd.Series([1, 2, 3], name="scores")
print(s.name) # "scores"copy
データをコピーするかどうかを指定します。
copy=Trueの場合、dataから独立したコピーを作成します。copy=Falseの場合、可能なら元データを参照します(ただし必要に応じてコピーが作られることもある)。
大きな配列を扱う場合、メモリ効率に影響することがあります。
fastpath(内部利用)
- 通常は利用しない内部引数です。
- Pandas内部でSeriesを高速に生成するために使われており、ユーザーが指定する場面はほぼありません。
- ドキュメント上では
<no_default>とされ、一般利用を想定していません。
まとめ
- 必須は
data(ただし省略すると空のSeriesが生成される)。 indexで要素にラベルを付与できる。dtypeはデータ型の強制。nameはSeriesに識別用の名前を付与。copyはデータを参照するかコピーするかの制御。fastpathは通常使わない内部向け。
ユーザーがよく使うのは data, index, dtype, name の4つです。
辞書型データを渡す時の注意点
Seriesに辞書型を渡すと、最初に辞書のキーがIndexになる。その後、コンストラクタ引数などでIndexを受け取ると、受け取った方のIndexで上書きしてしまい、値がすべてNaNになる。
この挙動は、辞書からSeriesを作るときのインデックス処理の順序に起因しています。ポイントを整理すると理解しやすいです。
Series生成の手順(辞書を渡した場合)
- まず辞書のキーがインデックスになる
- その後、
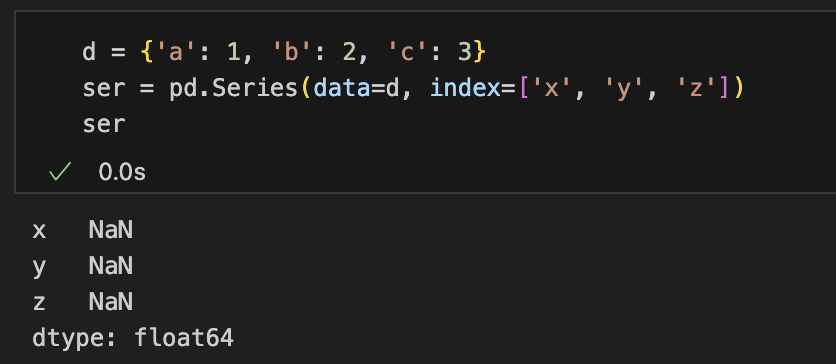
index引数が指定されていれば再インデックスが行われるindex=['x', 'y', 'z']を指定すると、もとのデータは{'a':1, 'b':2, 'c':3}ですが、
Pandasは「この辞書を一度Seriesにしたあと、インデックスを['x','y','z']に置き換える」という動きをします。 つまり- 元々のインデックス:
['a','b','c'] - 新しく指定されたインデックス:
['x','y','z']
- 元々のインデックス:
実際の挙動を確認
import pandas as pd
d = {'a': 1, 'b': 2, 'c': 3}
# 辞書からそのまま生成
ser1 = pd.Series(data=d)
print(ser1)
# a 1
# b 2
# c 3
# 辞書に含まれるキーと一致するindexを指定
ser2 = pd.Series(data=d, index=['a', 'c'])
print(ser2)
# a 1
# c 3
# 辞書に含まれないindexを指定
ser3 = pd.Series(data=d, index=['x', 'y', 'z'])
print(ser3)
# x NaN
# y NaN
# z NaNまとめ
- 辞書を
Seriesにするとき、最初にキーがインデックスになる。 indexを指定すると、その後に再インデックスが行われる。- 辞書のキーと
indexのラベルが一致しなければ、対応する値が見つからず NaNになる。
この挙動は「辞書のキーをデータのラベルとして解釈し、その後ユーザー指定のインデックスに合わせて揃える」ために起こる現象です。
dtypeとは何か
dtype(data type)は、SeriesやDataFrameの各列に格納されているデータの型を表します。
Pandas内部では基本的にNumPyのデータ型を利用しており、Series全体は単一のdtypeを持ちます。
dtypeの確認と指定
確認
s = pd.Series([1, 2, 3])
print(s.dtype) # int64指定
s = pd.Series([1, 2, 3], dtype="float32")
print(s)
# 0 1.0
# 1 2.0
# 2 3.0
# dtype: float32型変換(astype)
公式:https://pandas.pydata.org/docs/reference/api/pandas.Series.astype.html#pandas.Series.astype
Series.astype(dtype, copy=None, errors='raise')errors 引数は、"raise"(例外を投げる)か "ignore"(例外を無視) のどちらかのみ。
Seriesのdtypeは後から変換できます。
s = pd.Series([1, 2, 3])
s2 = s.astype("float64")
print(s2.dtype) # float64dtypeの種類
dtype 引数に指定できるものは大きく分けて下記の4種類
- 文字列(str)で指定する方法
- NumPyのdtypeオブジェクト
- pandasのExtensionDtype
- Pythonの組み込み型
NumPyのdtype(numpy.dtype)
NumPyで定義されるデータ型。Pandasの基本型もこれをベースにしています。
- 整数:
np.int8,np.int16,np.int32,np.int64 - 符号なし整数:
np.uint8,np.uint16,np.uint32,np.uint64 - 浮動小数:
np.float16,np.float32,np.float64 - 複素数:
np.complex64,np.complex128 - 論理値:
np.bool_ - 文字列:
np.str_ - バイト列:
np.bytes_ - オブジェクト型:
np.object_ - 日時:
np.datetime64 - 時間差:
np.timedelta64
pandasのExtensionDtype
Pandasが独自に提供している拡張データ型。NumPyでは表現しきれない型を扱えます。
pd.CategoricalDtype: カテゴリ型pd.StringDtype: 文字列型(欠損値に強い)pd.BooleanDtype: nullableなブール型pd.Int8Dtype,pd.Int16Dtype,pd.Int32Dtype,pd.Int64Dtype: 欠損値を許容する整数型pd.UInt8Dtype,pd.UInt16Dtype,pd.UInt32Dtype,pd.UInt64Dtype: 欠損値を許容する符号なし整数型pd.Float32Dtype,pd.Float64Dtype: 欠損値を許容する浮動小数型pd.DatetimeTZDtype: タイムゾーン付きの日時型pd.PeriodDtype: 期間型(例: 月次や年次の周期データ)
Pythonの組み込み型(type)
PandasはPythonの標準型も受け付けます。内部的には対応するNumPy dtypeに変換されます。
int→ 通常はint64float→ 通常はfloat64bool→boolstr→objectまたはstringdtypecomplex→complex128object→ 任意オブジェクト格納用
まとめ
dtypeは Seriesの内部データ型 を表す属性。- 基本的にはNumPyの型が使われる。
objectは文字列や混在データを表す汎用型。- 明示的に
dtypeを指定したり、astypeで変換可能。
これにより、数値演算や統計処理を効率よく行えるようになっています。
astype以外の型変換
astype は型の「鋳型」変換で、無効値を救済(NaN/NaTに置換)しません。
例外処理に相当する振る舞い(無効値を NaN/NaT に落とす等)をしたい場合は、パーサである pd.to_numeric/pd.to_datetime/pd.to_timedelta を使います。これらは errors 引数で挙動を制御できます。
Series.astype(..., errors=...)のerrorsは'raise'か'ignore'のみ。'ignore'は「変換せず元のオブジェクトを返す」だけpd.to_numeric/pd.to_datetime/pd.to_timedeltaはerrors={'raise','coerce','ignore'}をサポートし、'coerce'で無効な値をNaN/NaTにできる
公式:to_numeric / to_datetime / to_timedelta
最小例
s_num = pd.Series(['1', '2', 'x'])
pd.to_numeric(s_num, errors='coerce') # => [1.0, 2.0, NaN]
# astype だと:
# s_num.astype(float) -> ValueError('x' が数値でない)
# s_num.astype(float, errors='ignore') -> 変換せず object のまま返す
s_dt = pd.Series(['2025-01-01', 'not a date'])
pd.to_datetime(s_dt, errors='coerce') # => [2025-01-01, NaT]
s_td = pd.Series(['1 days', 'oops'])
pd.to_timedelta(s_td, errors='coerce') # => [1 days, NaT]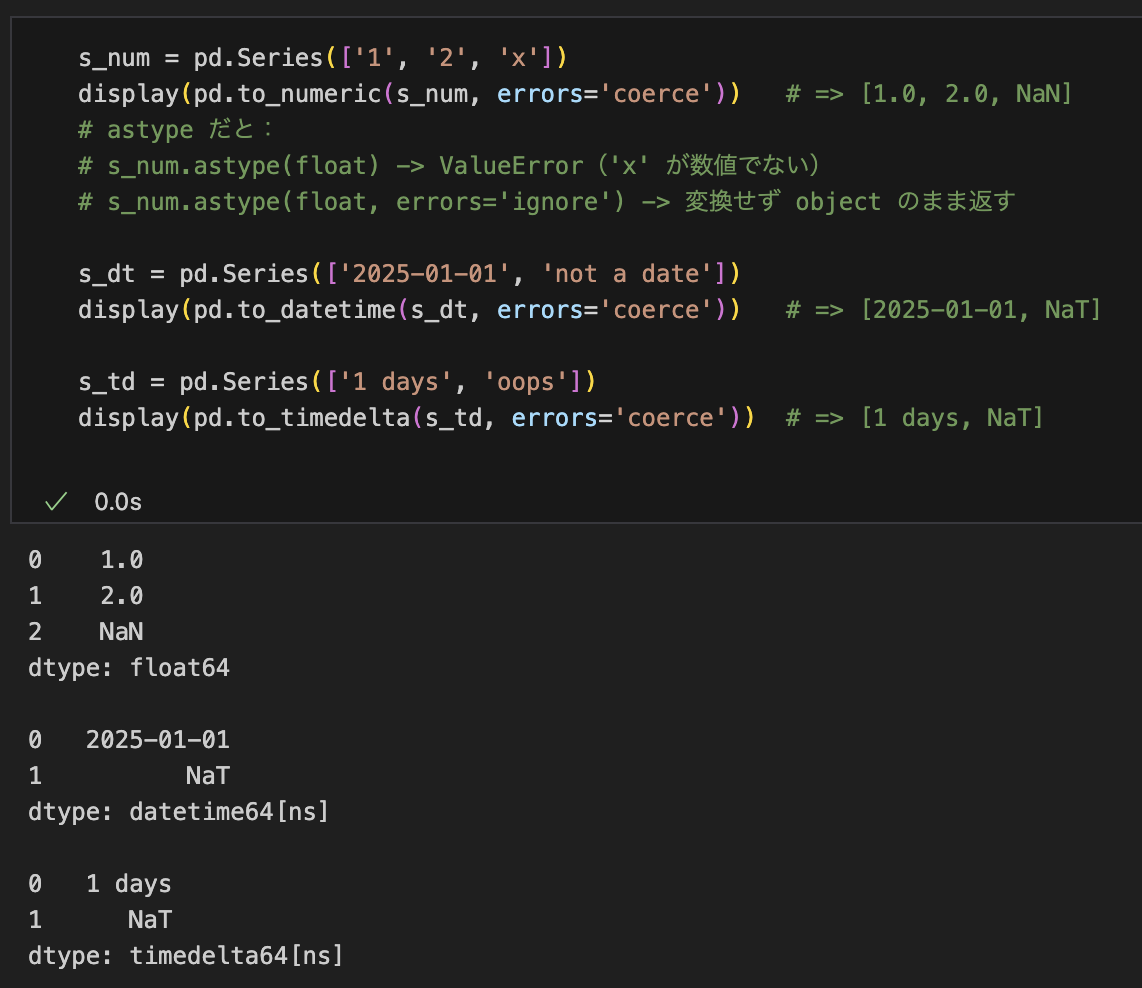
使い分けの指針
- データが既に一貫しており、単に dtype を揃えたい →
astype - 文字列などを「解釈」して型化し、無効値を救済したい →
to_numeric/to_datetime/to_timedelta(errors='coerce'を活用)
Seriesでの条件フィルタ 基本と実用テクニック
ブールマスク(最基本)
Seriesに条件式を適用すると、同じ長さのTrue/False配列(ブールマスク)が返り、これで抽出します。
s = pd.Series([12, 5, 17, 3, 9], index=list("abcde"))
print(s[s > 10]) # 10より大きい要素
print(s[(s >= 5) & (s <= 15)]) # 複数条件は & / | / ~ と()で優先順位を明示&(AND)、|(OR)、~(NOT)は必ず括弧で囲むand/or/notは使わない(要素単位演算でないため)
isin(集合による抽出)
s = pd.Series(["red", "blue", "green", "blue"])
print(s[s.isin(["blue", "green"])])
# 1 blue
# 2 green
# 3 blue
# dtype: objectインデックスに対して行う場合は s.index.isin([...]) を使います。
print(s[s.index.isin([2, 3])])
# 2 green
# 3 blue
# dtype: object範囲条件は between
両端の包含/非包含を選べます。Indexはbetweenなし
s = pd.Series([1, 2, 3, 4, 5])
s[s.between(2, 4, inclusive="both")] # 2〜4を含む
s[s.between(2, 4, inclusive="left")] # 2は含むが4は含まない文字列条件は .str アクセサ
NaNを含む場合は na=False を指定すると安全です。
s = pd.Series(["Tokyo", "Osaka", None, "Kyoto"])
# 部分一致(正規表現)。大小無視し、NaNは不一致扱い
s[s.str.contains("o", case=False, na=False)]
# 完全一致・前方/後方一致
s[s.str.fullmatch(r"[A-Za-z]+", na=False)]
s[s.str.startswith("K", na=False)]
s[s.str.endswith("a", na=False)]
# 複数語のいずれかを含む(正規表現を使わずリテラル検索)
s[s.str.contains("Tokyo|Osaka", regex=True, na=False)]
s[s.str.contains("Kyoto(市)?", regex=True, na=False)]正規表現を使わないリテラル検索なら regex=False を指定します。
s[s.str.contains("(", regex=False, na=False)] # 文字 "(" を含む行日時条件は .dt アクセサ
s = pd.Series(pd.to_datetime([
"2024-12-31", "2025-01-01", "2025-03-10", None
]))
# 年・月などの成分で絞り込み
print(s[s.dt.year == 2025])
print(s[(s.dt.month >= 1) & (s.dt.month <= 3)])
# 期間で絞り込み
start, end = pd.Timestamp("2025-01-01"), pd.Timestamp("2025-03-31")
print(s[(s >= start) & (s <= end)])タイムゾーン付きの場合は比較対象も同じTZに揃えます。
欠損値(NaN)条件
s = pd.Series([1.0, None, 3.0])
print(s[s.isna()]) # 欠損だけ
print(s[s.notna()]) # 欠損以外ブールインデックス vs where / mask
形を保ったまま条件に合わない要素を NaN にしたい場合は where、逆はmask。
ブールインデックス(s[s>=10])は要素数が減るのに対し、where はサイズを維持します。後続処理(元の位置情報が必要など)で使い分けます。
s = pd.Series([10, 2, 30, 4])
s.where(s >= 10) # 10未満をNaNにする(長さは変わらない)
s.mask(s >= 10) # 10以上をNaNにする
s.where(s >= 10, other=0) # 置換値を指定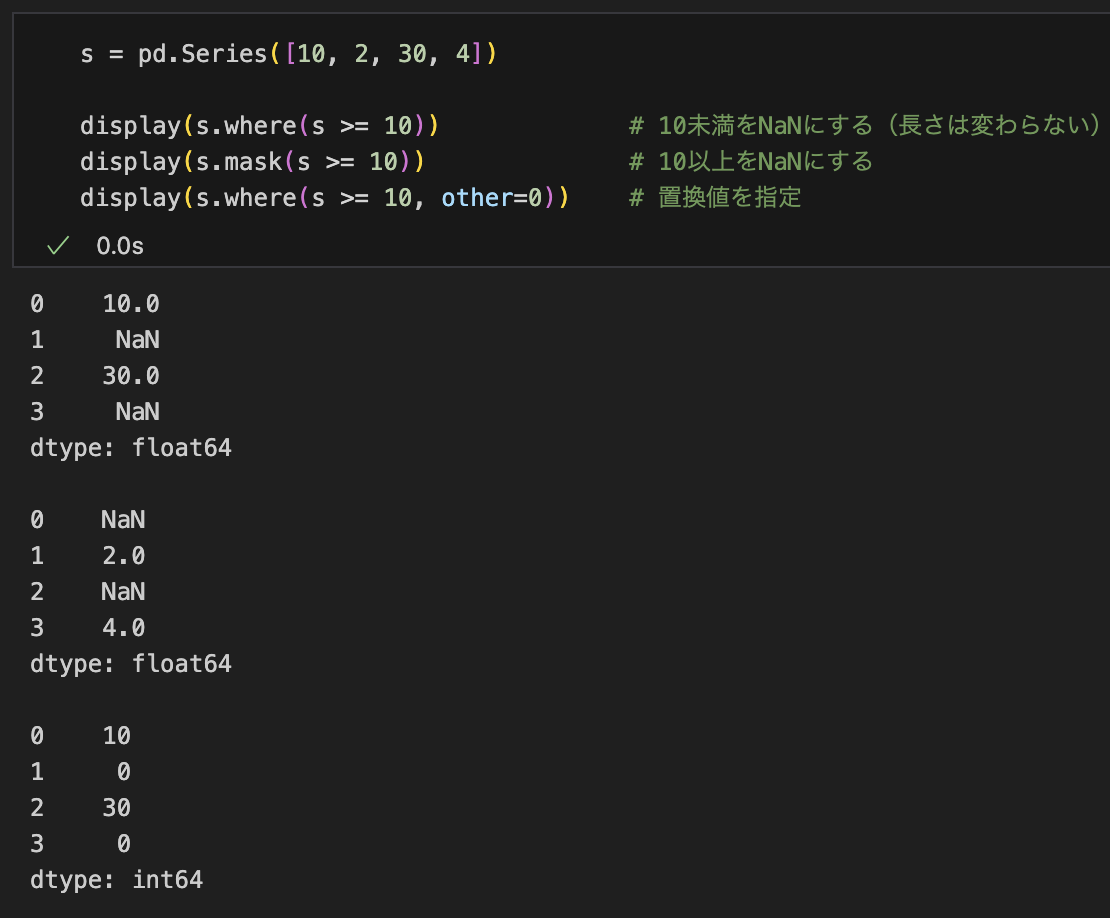
clip でしきい値を「はさむ」
抽出ではなく変形ですが、上下限を超える値を丸めたいときに便利です。
s = pd.Series([-3, 0, 5, 12])
s.clip(lower=0, upper=10) # 負は0に、10超は10に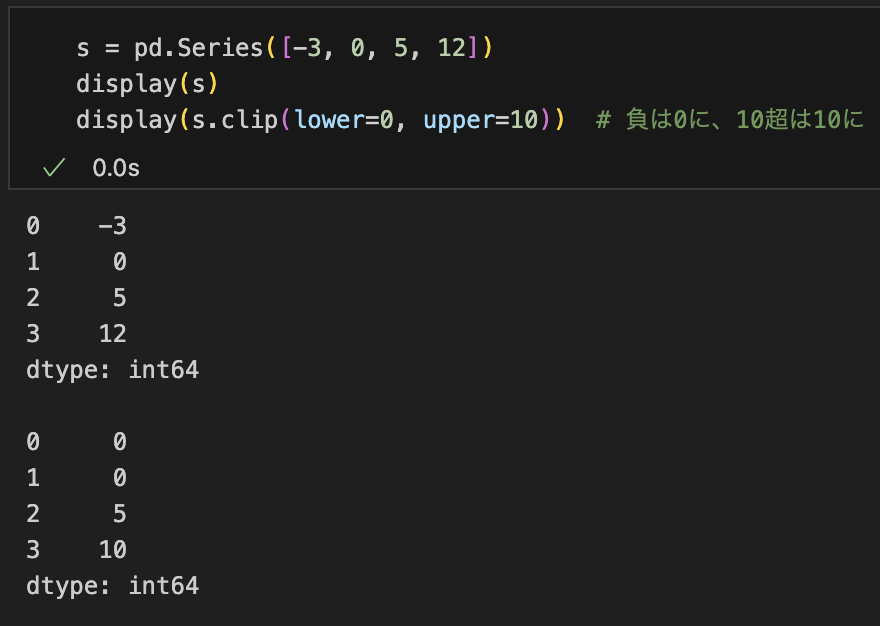
nlargest / nsmallest(上位/下位抽出)
条件式ではないものの、ランキング的抽出に有用です。
s = pd.Series([5, 1, 7, 3, 9])
s.nlargest(3) # 値の大きい上位3件
s.nsmallest(2) # 値の小さい上位2件注意点:パフォーマンスと落とし穴
- 文字列の大量検索は正規表現が重くなりがち。単純一致は
regex=Falseを選ぶ - 複数条件は括弧で明確化する(
s > 0 & s < 10は誤り。正しくは(s > 0) & (s < 10)) and/or/notは使わず&/|/~を使う- 文字列と数値が混在し
objectになっていると比較ができないことがある。前処理でto_numeric(..., errors="coerce")等を使って整形してから条件式にかける
まとめコード(よくある条件の寄せ集め)
import pandas as pd
import numpy as np
# サンプルSeries
s_num = pd.Series([10, -1, 5, 20, np.nan], index=list("abcde"))
s_str = pd.Series(["apple", "Banana", None, "blue berry", "avocado"], index=list("abcde"))
s_dt = pd.Series(pd.to_datetime(["2025-01-01","2025-02-15",None,"2025-03-10","2024-12-31"]))
# 数値条件
pos = s_num[s_num > 0]
rng = s_num[s_num.between(5, 15, inclusive="both")]
nan_or_big = s_num[s_num.isna() | (s_num >= 10)]
# 文字列条件
has_berry = s_str[s_str.str.contains("berry", case=False, na=False)]
starts_with_a = s_str[s_str.str.startswith("a", na=False)]
literal_paren = s_str[s_str.str.contains("(", regex=False, na=False)]
# 集合とインデックス条件
subset = s_str[s_str.isin(["apple", "avocado"])]
by_idx = s_str[s_str.index.isin(["a","e"])]
# 日付条件
q1_2025 = s_dt[(s_dt >= "2025-01-01") & (s_dt < "2025-04-01")]
feb_only = s_dt[s_dt.dt.month == 2]
# where/mask で形を維持
masked = s_num.where(s_num >= 0) # 負をNaN
filled = s_num.where(s_num >= 0, other=0)
このセットを押さえておくと、ほとんどの抽出要件に対応できます
Seriesのデータを加工する方法
基本方針
- まずは「ベクトル化」されたメソッドで処理する
- 次に
.str(文字列)や.dt(日時)など専用アクセサを使う - 最後の手段として
apply()(要素ごと関数適用)を使う
この順にすると、速くて読みやすく、バグも出にくいです。
算術・論理(最速の部類)
s = pd.Series([10, 20, 30])
s2 = (s + 5) * 2
flag = (s >= 15) & (s <= 25)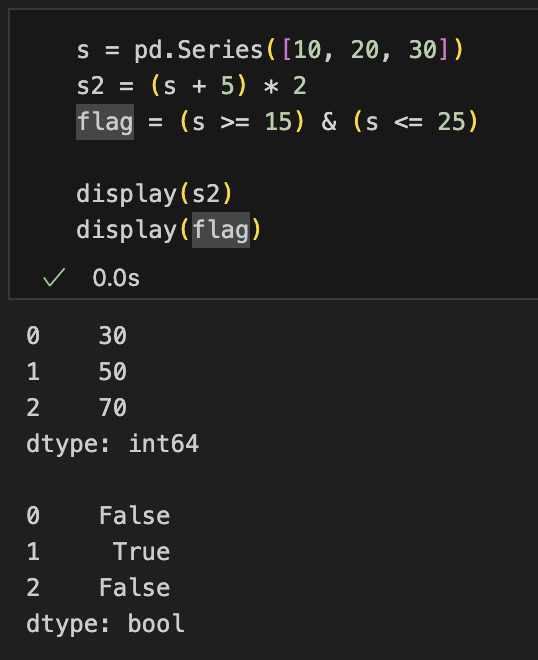
置換・マッピング
メモ: 単純な値対応なら map/replace が apply より高速・簡潔。
s = pd.Series(["A", "B", "C", "B"])
s.replace({"B": "Bee"}) # 値の置換(部分一致や正規表現も可)
s.map({"A": 1, "B": 2}) # 辞書・Series・関数で要素変換(存在しないキーはNaN)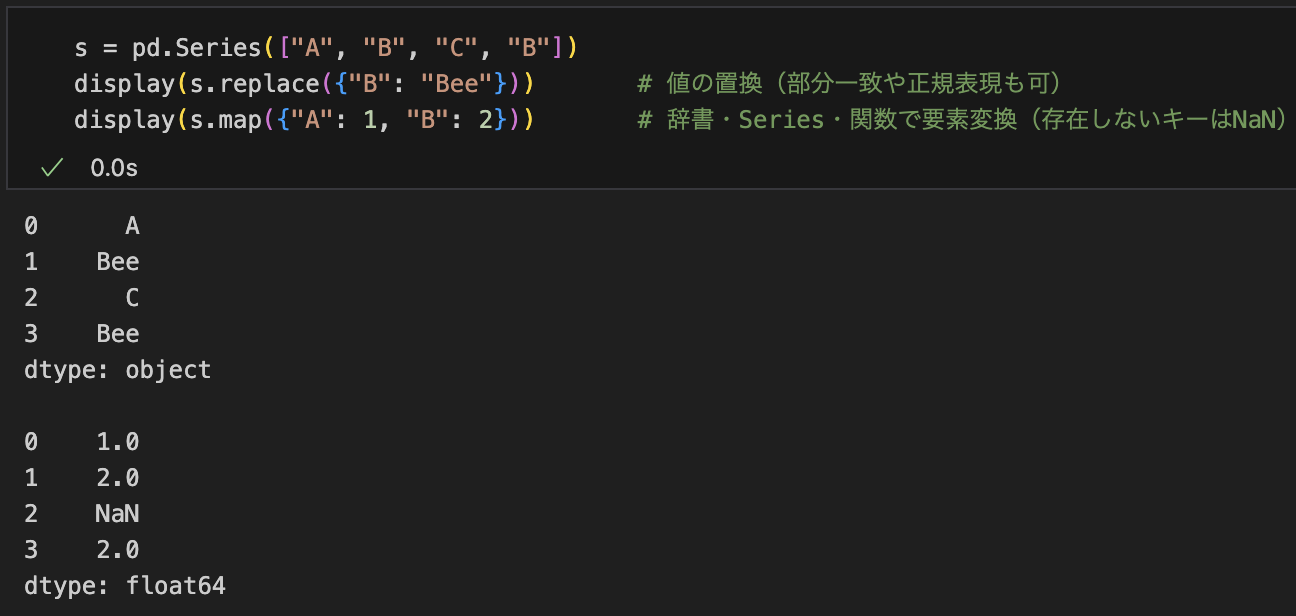
欠損値の扱い
s.fillna(0) # 一括補完
s.fillna(method="ffill") # 前方補完
s.interpolate() # 数値の補間条件に応じた置換・丸め込み
s.where(s >= 0, other=0) # 条件を満たさない要素を0に
s.mask(s > 100, other=100) # 条件を満たす要素だけ置換
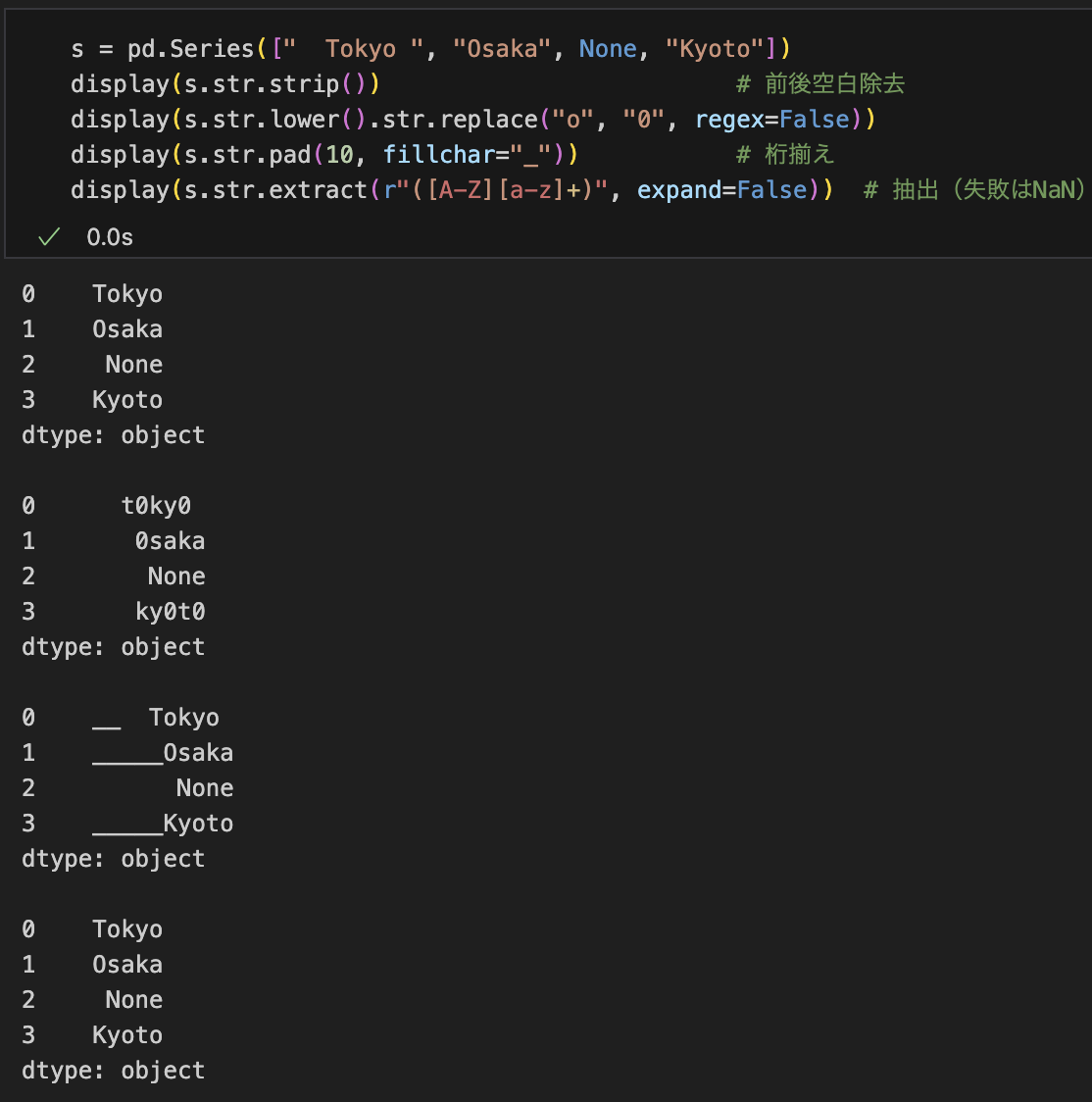
s.clip(lower=0, upper=100) # しきい値ではさむ文字列の加工(.str アクセサ)
s = pd.Series([" Tokyo ", "Osaka", None, "Kyoto"])
s.str.strip() # 前後空白除去
s.str.lower().str.replace("o", "0", regex=False)
s.str.pad(10, fillchar="_") # 桁揃え
s.str.extract(r"([A-Z][a-z]+)", expand=False) # 抽出(失敗はNaN)na= や regex= を適切に指定して安全・高速に。
並べ替え・ランキング・丸め
s.sort_values(ascending=False)
s.rank(method="average") # 順位付け
s.round(2) # 小数点丸めローリング・拡張(移動ウィンドウ処理)
s = pd.Series([1, 2, 3, 4, 5])
s.rolling(window=3).mean() # 移動平均
s.expanding().sum() # 累積計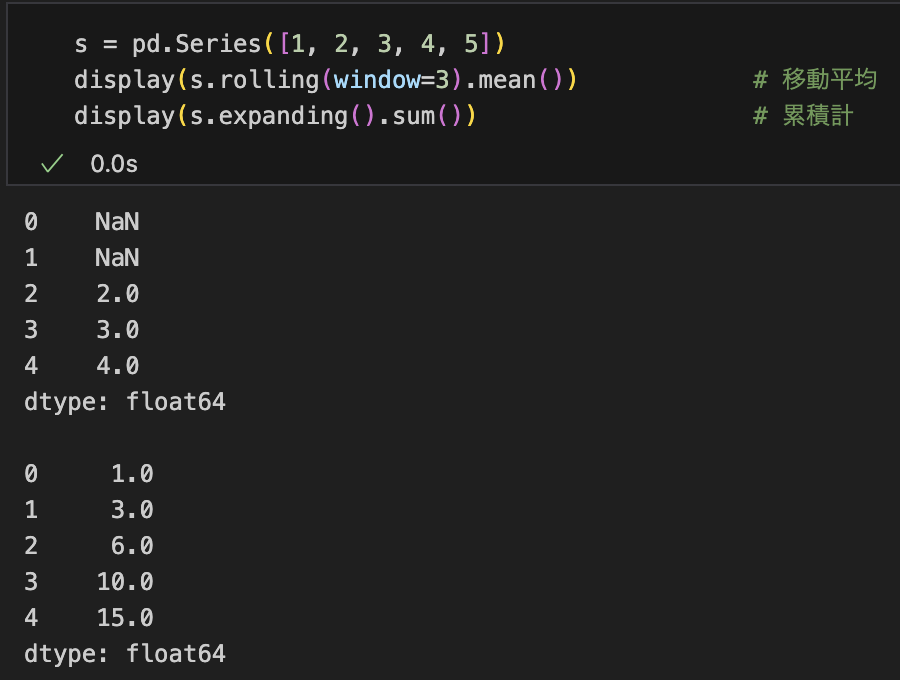
apply() を使うべき場面
- ベクトル化しづらい複雑な変換(外部ライブラリを呼ぶ、複合ルール)
- ただし、
applyは要素ごとのPythonループになるため遅くなりやすい
def score_to_band(x):
if pd.isna(x): return x
return "A" if x >= 80 else ("B" if x >= 60 else "C")
s = pd.Series([95, 72, 50, None])
s.apply(score_to_band)戻り値は各要素に対するスカラー/オブジェクトになります。Series.apply は返り値を自動で列展開しません(リストを返すと「リストを要素にもつSeries」になります)。列展開が必要なら DataFrame 側の apply(..., result_type="expand") を使います。
map と apply の使い分け
- 「1対1の写像」なら
map(辞書やSeriesを渡せる、速い・簡潔) - 「任意の関数で加工したいがベクトル化できない」ときに
apply - 可能なら
.str/.dt/ 演算子 / 専用メソッドでベクトル化するのが最優先
パフォーマンスと注意点
- まずベクトル化(算術・
.str・.dt・map・replace・where/mask)を検討 applyは遅くなりやすい。どうしても必要な箇所に限定- 型混在(
object)は計算が遅くエラーも出やすい。前処理でto_numeric等で揃える - 文字列検索は不要な正規表現を避けて
regex=Falseを活用 - 日時の比較はタイムゾーンを揃える
この流れを押さえておけば、apply()に頼りすぎず、速くて読みやすいSeries加工が実現できます
Series同士の処理
まずは大原則:インデックスで自動アラインメント
Series 同士の演算・結合はインデックスをキーにそろえて行われます。ラベルが一致しない位置は欠損(NaN)になります。
s1 = pd.Series([1, 2, 3], index=["a","b","c"])
s2 = pd.Series([10, 20, 30], index=["b","c","d"])
s1 + s2
# a NaN
# b 12.0
# c 23.0
# d NaNアラインメントを回避したい(単純に位置で計算したい)場合は .to_numpy() で配列化するとよいですが、インデックス情報は失われます。
pd.Series(s1.to_numpy() + s2.to_numpy(), index=s1.index) # 位置ベースで計算
# a 11
# b 22
# c 33
# dtype: int64算術演算:演算子 or “flex”メソッド+fill_value
+ - * / // % **はそのまま使える- 欠損を埋めてから計算したいなら flexメソッド を使う(
add/sub/mul/div/floordiv/mod/pow)
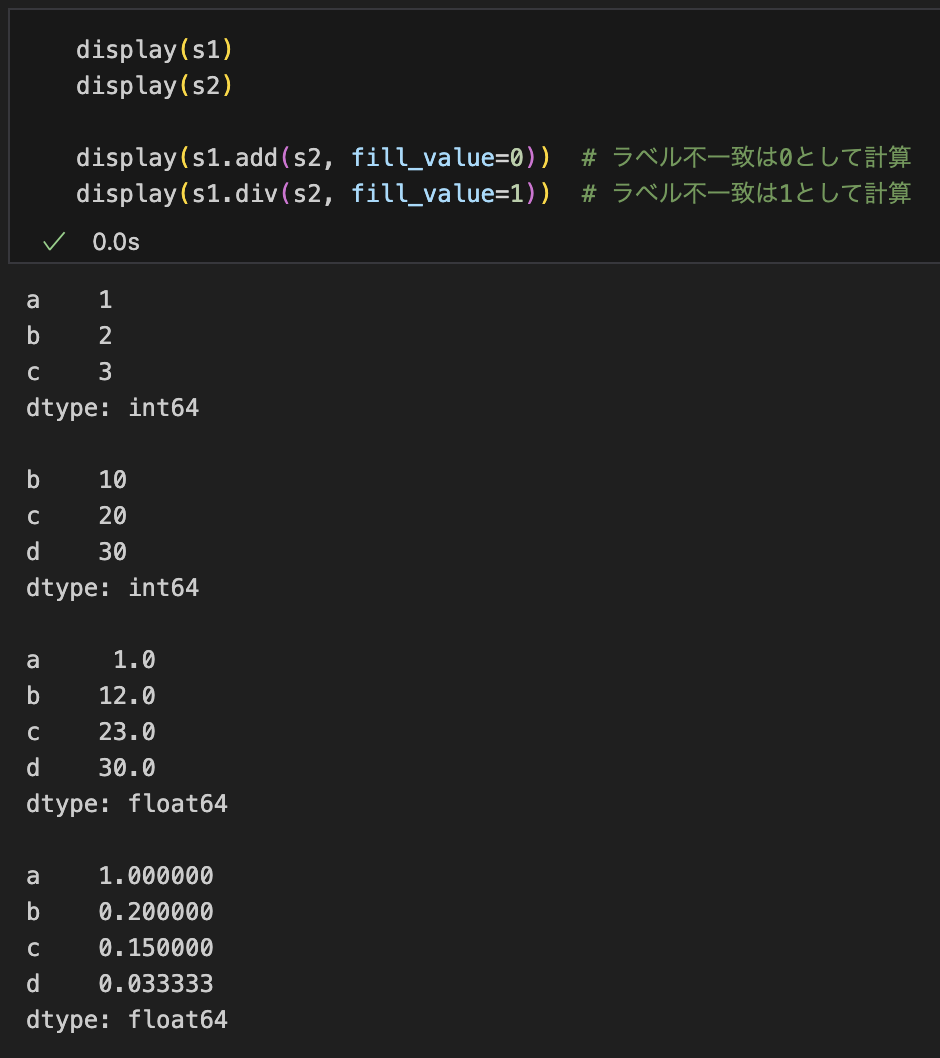
s1.add(s2, fill_value=0) # ラベル不一致は0として計算
s1.sub(s2, fill_value=0)
s1.mul(s2, fill_value=1)
s1.div(s2, fill_value=1)左右を入れ替えたバージョン radd/rsub/... もあります。
論理・比較演算もアラインメント
ブール演算は & | ~、比較は eq/ne/lt/le/gt/ge(または ==, !=, < など)。
(s1 > 1) & (s2 < 25) # ラベル一致部分のみブールが立つ
s1.eq(s2, fill_value=0) # 欠損を0扱いで比較要素ごとの合成:combine と combine_first
combine(other, func)は対応する要素を関数で合成
import numpy as np
s1.combine(s2, func=lambda x, y: np.nanmax([x, y])) # 要素ごとの最大combine_firstは左を優先し、NaNを右で埋める(名前どおり“firstを優先”)
s1.combine_first(s2) # 左s1の欠損だけをs2で補完
# 同等の書き方: s1.fillna(s2)where/mask を相手Seriesと組み合わせる
条件がもう一方の Series で決まるときに便利。
# s2が閾値として働く例:s1がs2未満ならそのまま、以上ならs2で上限
s1.where(s1 < s2, other=s2)
# 逆に条件を満たす箇所だけ置換
s1.mask(s1 > s2, other=s2)結合(縦=行方向)と横結合(列方向)
- 縦結合(積み上げ):
pd.concat([s1, s2])
1本の長いSeriesにする(インデックスが重複し得る)
pd.concat([s1, s2])- 横結合(列として並べる):
axis=1で DataFrame に
df = pd.concat([s1, s2], axis=1) # 列方向に並べる(インデックスでアライン)
df.columns = ["s1", "s2"]- 既存のDataFrameに Series を列として加えるなら
df.join(s2)も有効(s2をto_frame()せずにOK)
アラインを明示する:align
事前に同じインデックス集合に揃える(join で union/intersection を選べる)。
s1a, s2a = s1.align(s2, join="outer", fill_value=0) # 全キーに広げて0埋め
s1a + s2ajoin は "outer"|"inner"|"left"|"right"。fill_value を指定すると欠損を埋めて返せます。
差分・比較の可視化:compare と update
compare:異なる箇所だけを抽出(左右の値を並べる)
s1.compare(s2, align_axis="index") # 差分のみ(同値は落ちる)update:左Seriesの位置に合わせて、対応する右の非NaNで上書き(戻り値はNone、左を就地変更)
s = s1.copy()
s.update(s2) # s のうち s2 が非NaNのラベルだけ置換される相関・共分散など統計(アライン済み領域だけで計算)
s1.corr(s2) # ピアソン相関
s1.cov(s2) # 共分散MultiIndexでも同様にラベルで揃う
多階層インデックスでも完全一致のキーでアラインされます。必要に応じて reindex や swaplevel、sort_index を併用。
欠損を先に処理してから演算する定番パターン
# 片方が欠損のときに0として扱って和を取りたい
s_sum = s1.fillna(0).add(s2.fillna(0))
# あるいは align で一気に埋める
s1a, s2a = s1.align(s2, join="outer", fill_value=0)
s_sum = s1a + s2aパフォーマンスの勘所
- 可能なら 演算子よりも flexメソッド+fill_value を使うと補完を1ステップで済ませられる
- 何度も同じ相手と計算するなら一度
alignで揃えてから複数の演算を行うと効率的 - アライン無しの位置ベース演算は
.to_numpy()/.arrayで。ただしラベル安全性は失うため用途を限定
使い分け早見表
- 欠損を特定値扱いで演算したい →
add/sub/...にfill_value=... - 片方で欠損を埋めたい →
combine_first(またはfillna(other)) - 条件に応じてもう片方の値を使いたい →
where/mask - 差分だけ見たい →
compare - まとめて同じラベル集合に整えたい →
align(join=..., fill_value=...) - Seriesを横に並べたい →
pd.concat([...], axis=1)(DataFrame化) - 片方の非NaNで上書きしたい(位置基準) →
update
このセットを押さえておけば、Series 同士の結合・演算はほぼ網羅できます。