ここでは、PandasのSeriesを使って「抽出」「変更」「集計」「グループ化」「集合」を一通り押さえます。例は次のサンプルから始めます。
import pandas as pd
import numpy as np
s = pd.Series([10, 20, 30, 40, np.nan, 50], index=list("abcdef"))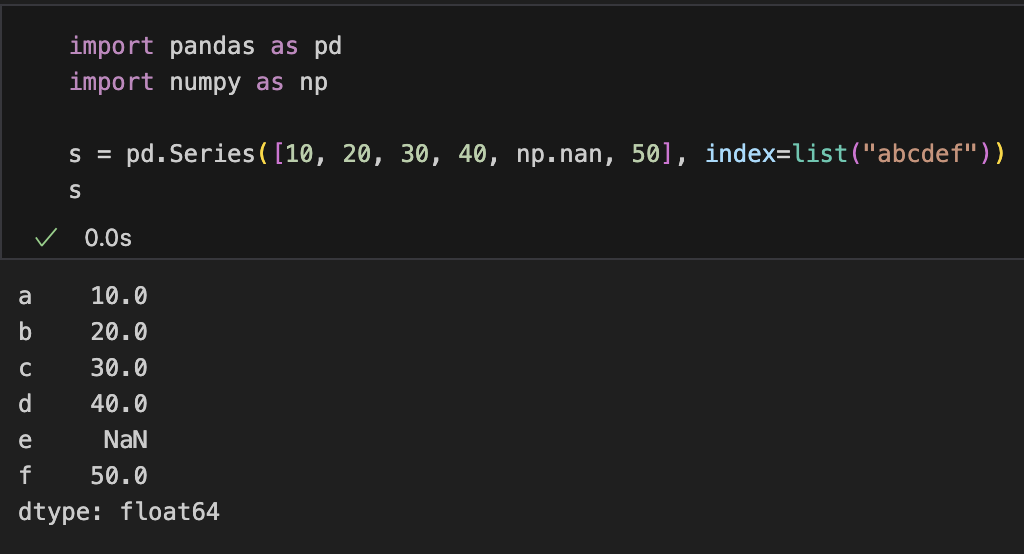
抽出
基本は位置で取るか、ラベルで取るか、条件で取るかの3系統です。
# 位置ベース(0始まり、右端は含まない)
s.iloc[0] # 10
s.iloc[1:4] # 20,30,40
# ラベルベース(スライスは右端を含む)
s.loc["a"] # 10
s.loc["b":"d"] # b,c,d の3要素
# 複数要素の抽出(位置・ラベルいずれもOK)
s.iloc[[0, 2, 5]]
s.loc[["a", "c", "f"]]
# 真偽インデックス(条件抽出)
s[s > 25] # 30,40,50
s[s.isna()] # 欠損のみ
s[s.between(20, 40)] # 20〜40を含む
# よく使う取り出し
s.head(3)
s.tail(2)
s.sample(2, random_state=0)
# 文字列/日付のヘルパ(Seriesのdtypeが該当する場合)
# 例: 文字列長が3以上
# s.str.len().ge(3)
# 日付の月で抽出
# s.dt.month.eq(1)ilocは常に位置、locはラベル。スライスの端点の扱いが異なる。- ビュー/コピーの違いによる警告を避けるには、抽出→代入のとき
locを明示して書くのが安全。
変更
単一・複数・条件付きの代入、型変換、要素置換など。
# 単一・複数要素の書き換え
s.loc["b"] = 21
s.loc[["c", "d"]] = [31, 41]
# 条件付き代入
s.loc[s.isna()] = 0 # 欠損を0に
s = s.mask(s < 0, 0) # 条件を満たす要素を置換
s = s.where(s >= 20, other=20) # 条件を満たさない要素だけ置換
# 欠損処理
s = s.fillna(0)
s = s.ffill() # 直前の有効値で埋める
s = s.bfill() # 直後の有効値で埋める
# 値の一括置換・変換
s = s.replace({21: 22})
s = s.astype("int64") # 型変換(欠損があると失敗することに注意)
s = s.clip(lower=20, upper=45) # 範囲に切り詰め
s = s.round(0) # 丸め
# 関数適用(要素ごと)
s = s.map(lambda v: v * 2)
# インデックス操作
s = s.rename(index={"a": "A"})
s = s.set_axis([*s.index[:-1], "Z"]) # 最後のラベルをZに(長さは一致させる)- 条件代入は
locとセットで書くと意図が明確。 - 文字列なら
s.str.replace、日付ならs.dt.floorなど dtypeごとのアクセサが便利。 - 破壊的変更がイヤなら右辺に代入して新Seriesとして持つ。
集計
Series単体でも豊富な集計が可能です。
s.sum() # 合計
s.mean() # 平均
s.median() # 中央値
s.min(), s.max() # 最小・最大
s.var(), s.std() # 分散・標準偏差
s.nunique() # ユニーク数
s.value_counts() # 値ごとの出現回数(降順)
s.describe() # 代表統計量のまとめ
# True/Falseの集計
(s > 30).mean() # 比率(True=1, False=0として平均)
(s > 30).sum() # 件数
# 位置を返す集計
s.idxmax() # 最大値のラベル
s.idxmin() # 最小値のラベル
# 複数集計を一度に
s.agg(["mean", "median", "max"])
# 欠損の扱い(skipna)
s.sum(skipna=False)- 論理Seriesはsum()で件数、mean()で割合を手早く出せる。
value_counts(normalize=True)で割合に変換できる。
グループ化
Seriesでも groupby は使えます。キーはインデックスでも値でも構いません。
# 値側をキーにして集計(例: 値を10の位で丸めてグルーピング)
key = (s // 10) * 10
s.groupby(key).mean()
# インデックスでグループ化
# 例: 先頭文字(大文字/小文字に正規化して)ごとに合計
s2 = pd.Series([1,2,3,4], index=["aa","Ab","bc","bD"])
s2.groupby(s2.index.str[0].str.lower()).sum()
# 関数でグループキーを動的生成
s.groupby(lambda idx: 0 if idx < "m" else 1).count()
# 複数集計
s.groupby(key).agg(["count", "mean", "max"])
# グループごとの変形(各要素に集計結果を戻す)
s.groupby(key).transform("mean") # 同じキー内の平均を各要素に対応づけ応用
- 日付Seriesなら
s.groupby(s.dt.month).mean()のように.dtアクセサを多用。 - DataFrameと同様に
resample(時系列の等間隔集計)もSeriesで利用可能。
集合
- 共通部分(intersection)
→ 両方にある要素 - 和集合(union)
→ どちらか一方以上に含まれる要素 - 差集合(difference)
→ 「AにはあるがBにはない要素」だけを残す(順序を逆にすると結果が変わる) - 対称差(symmetric difference)
→「AかBのどちらかにあるが、両方にはない要素」(両方の差集合をまとめたもの。XORと同じ考え方)
Pandas/Seriesでの実装例
集合演算についてはPython組み込みのsetと組み合わせたり、NumPy関数を使うのが分かりやすいです
import pandas as pd
sA = pd.Series([1, 2, 3, 4])
sB = pd.Series([3, 4, 5, 6])
# Pythonの集合を使う
setA, setB = set(sA), set(sB)
setA & setB # {3, 4} 共通部分(intersection)
setA | setB # {1, 2, 3, 4, 5, 6} 和集合(union)
setA - setB # {1, 2} 差集合(difference)
setA ^ setB # {1, 2, 5, 6} 対称差(symmetric difference)
# NumPyでやる場合
import numpy as np
np.intersect1d(sA, sB) # array([3, 4])
np.union1d(sA, sB) # array([1,2,3,4,5,6])
np.setdiff1d(sA, sB) # array([1, 2])
np.setxor1d(sA, sB) # array([1,2,5,6])「比較」との違い
- 比較 (comparison)
→ 一般的には>や==のように「要素ごとの大小・等しいか」を調べる処理。
(例:sA == sBで同じ位置の要素を比較) - 集合 (set operations)
→ 全体として「どんな要素を持っているか」を軸にした演算。
(例: 「sAにもsBにも存在する値は?」)